ON THIS PAGE
Progress0%





Our Global Presence :

Selecting the right AI inference platform is now a business imperative as companies move from experimentation to real-world deployments. Nearly 78% of organizations use AI in at least one business function, marking rapid integration across sectors, with generative AI adoption climbing to 71% in 2024–2025.
In addition, the global AI inference server market is projected to reach USD 18.31 billion in 2026, reflecting heightened demand for real-time AI workloads and low-latency performance.
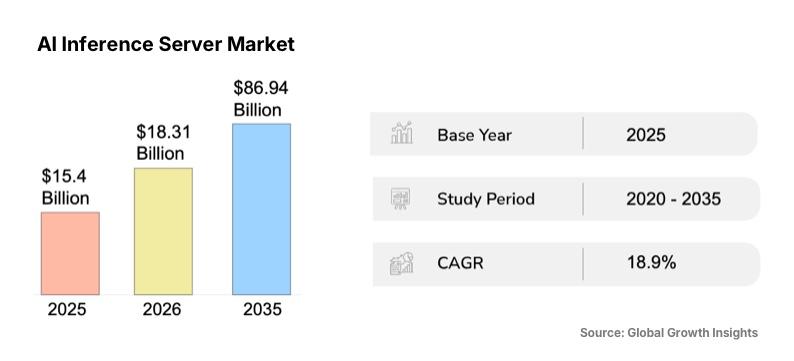
As models proliferate and workloads diversify, understanding inference platforms—how they differ, scale, and support production workloads—matters for cost, performance, and competitive advantage.
This guide breaks down core components, comparison criteria, top providers, and practical use cases for businesses evaluating AI inference solutions in 2026.
An AI inference platform is the production layer that runs trained machine learning models and delivers predictions to applications, users, or systems. It focuses on speed, reliability, and cost control rather than training. The platform manages request handling, scaling, hardware utilization, model versions, and monitoring, ensuring AI models perform consistently under real-world workloads and changing traffic conditions.
Performance optimization centers on minimizing latency and maximizing throughput. This includes techniques like model quantization, batching, caching frequent requests, and optimizing runtime engines. The goal is simple: return accurate outputs as fast as possible without wasting compute.
Well-designed AI inference software exposes tuning controls while handling low-level optimizations automatically. This matters when inference workloads spike or when models grow larger and more complex.
Scalability determines whether an inference platform can handle fluctuating traffic without service degradation. This includes autoscaling across nodes, load balancing, and graceful handling of burst traffic.
The best infrastructure for scalable AI inference platforms adjusts resources dynamically. It avoids overprovisioning during quiet periods and prevents failures during peak demand. For customer-facing AI features, this is non-negotiable.
Modern inference relies heavily on specialized hardware. GPUs, TPUs, and custom AI inference chip accelerate matrix operations and reduce response times. Some platforms also support edge devices with NPUs or optimized CPUs.
The platform’s ability to match models to the right hardware directly impacts cost efficiency and latency. Hardware abstraction layers help teams, or AI consultants deploy across different environments without rewriting infrastructure logic.
Model management covers versioning, deployment, rollback, and lifecycle control. It ensures teams can update safely, test changes, and revert quickly if issues arise.
Strong model governance also supports auditability and traceability. This becomes essential in regulated industries and enterprise environments where explainability and accountability matter.
Cloud providers offer managed AI inference services as part of broader cloud ecosystems. These platforms integrate tightly with storage, networking, security, and MLOps tools, making them a natural choice for teams or AI app development services already operating in a specific cloud environment. They abstract most infrastructure concerns and support a wide range of models and deployment patterns.
Cloud AI inference companies prioritize reliability, global availability, and enterprise governance, often trading raw cost efficiency for convenience and operational simplicity.
Pros
Cons
Specialist inference providers focus almost entirely on running models efficiently in production. They optimize for latency, throughput, and cost per inference, often using aggressive batching, model compression, and hardware-specific tuning. These platforms are designed for teams with high-volume or performance-sensitive workloads, such as real-time AI products.
Specialist providers typically move faster than large clouds when adopting new models and hardware, but offer fewer adjacent platform services.
Pros
Cons
Foundation labs provide inference platforms centered on their own proprietary models. These providers control the full stack, from model architecture to deployment and safety systems. Their inference offerings emphasize output quality, reliability, and built-in safeguards rather than infrastructure flexibility.
Foundation labs are well-suited for teams that want access to state-of-the-art models without managing training or optimization. However, customization and portability are often constrained by the provider’s platform boundaries.
Pros
Cons
AI inference hardware providers combine specialized chips with optimized software stacks to deliver high-performance inference. These platforms are designed to maximize throughput and minimize cost per request by tightly coupling hardware and runtime environments. They are commonly used in large-scale data centers or edge deployments where efficiency matters most.
While they can deliver substantial performance gains, adopting these platforms often requires deeper technical integration and operational expertise.
Pros
Cons
Related Read: Best AI Development Services Providers in 2026
Inference platforms differ in the models they support. Some focus on proprietary models, others emphasize open-source options, while many allow fine-tuning. The right choice depends on control requirements, customization depth, and whether long-term portability or vendor lock-in is acceptable for your product strategy.
Platforms with built-in retrieval, vector search, and grounding reduce system complexity. These features allow models to reference private or real-time data during inference. Integrated tooling improves response accuracy, lowers latency, and removes the need to maintain separate pipelines for search, storage, and inference.
Different applications produce different inference traffic patterns. REST works for interactive requests, batching improves throughput for bulk jobs, and streaming supports continuous outputs. A strong platform supports all three, allowing teams to optimize performance and AI development cost without redesigning infrastructure as workloads evolve.
Security and compliance determine whether an inference platform can be used in regulated environments. Certifications, access controls, encryption, and audit logs protect sensitive data. Platforms that meet standards such as ISO, SOC 2, HIPAA, or DoD requirements reduce legal risk and accelerate enterprise adoption.
Ease of setup affects how quickly teams can move from experimentation to production. Clear APIs, SDKs, documentation, and deployment workflows reduce engineering overhead. Platforms that simplify onboarding help teams focus on model behavior and application logic rather than infrastructure configuration and troubleshooting.
Inference pricing varies widely, including per-token, per-second, per-request, and reserved-capacity models. Understanding how costs scale with traffic and model size is critical. Transparent pricing helps teams forecast spend, avoid surprises, and align AI usage with business value and growth plans.
Performance includes latency, throughput, and stability under load. Benchmarks offer guidance, but real-world performance depends on traffic patterns and model complexity. Platforms should deliver predictable response times, efficient resource usage, and minimal variance during peak demand or model updates.
Scalability and reliability determine whether inference remains available as usage grows. Features like autoscaling, redundancy, failover, and multi-region support reduce downtime. Platforms with strong SLAs ensure AI-powered features remain dependable for customer-facing and mission-critical applications.

NVIDIA’s AI inference tools focus on maximizing model performance on GPU-based infrastructure. Built around TensorRT and Triton Inference Server, the platform enables highly optimized deployment of deep learning models across data centers and edge environments. It supports multiple frameworks and emphasizes low-latency, high-throughput inference.
NVIDIA’s tooling is widely used in production environments where performance predictability and hardware efficiency matter, especially for computer vision, speech, and large-language-model workloads.
Key Features
Pros
Cons
GMI Cloud provides GPU-first cloud infrastructure tailored specifically for AI inference and training workloads. The platform focuses on delivering access to high-performance GPUs with flexible deployment options and predictable pricing.
GMI Cloud is often used by teams that need scalable inference without the overhead of large hyperscaler platforms. Its value lies in offering simpler access to modern GPU hardware while maintaining control over performance and cost for sustained inference workloads.
Key Features
Pros
Cons
As one of the top innovative AI inference vendors, SiliconFlow specializes in optimized inference for large models, with a strong emphasis on efficiency and throughput. The platform focuses on reducing inference latency and compute costs through model optimization techniques and hardware-aware execution. It is designed for organizations deploying large language models or high-volume inference services.
SiliconFlow positions itself as a performance-focused alternative to general-purpose clouds, appealing to teams that need fine-grained control over inference behavior.
Key Features
Pros
Cons
Vertex AI is Google Cloud’s managed platform for deploying and running machine learning models at scale. They are among the most trustworthy AI inference provider in the market. Its inference capabilities integrate tightly with Google’s data, analytics, and MLOps tooling. Vertex AI supports both custom and prebuilt models and handles scaling, monitoring, and versioning automatically. The platform is designed for enterprise teams that want managed inference with strong reliability guarantees, governance controls, and seamless integration into existing Google Cloud environments.
Key Features
Pros
Cons
Replicate is an API-first inference software designed to make deploying and running machine learning models straightforward. It focuses on simplicity and speed, allowing teams to run models through a consistent interface without managing infrastructure.
Replicate is popular among developers, AI development companies, and startups experimenting with open-source and custom models. While it is not built for extreme scale, it works well for prototyping, moderate production workloads, and rapid iteration on model-driven features.
Key Features
Pros
Cons
OpenAI provides managed inference access to advanced foundation models through hosted APIs. The platform emphasizes output quality, safety, and reliability, abstracting away infrastructure and optimization complexity. OpenAI handles scaling, updates, and model improvements behind the scenes, allowing teams to focus on application logic. It is widely used for conversational AI, content generation, and reasoning tasks. However, inference is tied closely to OpenAI’s ecosystem and pricing structure.
Key Features
Pros
Cons
Hugging Face offers an inference platform built around open-source models and community-driven tooling. It supports hosted inference endpoints, on-demand deployment, and integration with popular ML frameworks.
Hugging Face is widely used by teams that value transparency, customization, and model portability. The platform balances ease of use with flexibility, making it suitable for both experimentation and production.
Performance tuning is possible, but often requires more hands-on configuration compared to fully managed services.
Key Features
Pros
Cons
Groq delivers inference using custom-built hardware designed for ultra-low-latency execution. Its architecture focuses on deterministic performance, making it well-suited for real-time and high-throughput workloads. Groq’s inference platform tightly integrates with its hardware, enabling models to run with predictable response times. This makes it attractive for time-sensitive applications. However, its specialized approach limits flexibility and requires alignment with Groq’s supported models and execution environment.
Key Features
Pros
Cons
AI inference platforms power real-time conversational systems such as chatbots, virtual assistants, and customer support agents. These applications require low latency, high availability, and consistent response quality. Inference platforms handle concurrent user requests, manage traffic spikes, and ensure predictable performance while supporting streaming outputs and integration with enterprise data sources.
Inference platforms support content generation workloads, including text, image, audio, and code creation. These systems often require high throughput and cost efficiency, especially at scale. Inference platforms optimize batching, caching, and hardware utilization to generate outputs quickly while maintaining consistent quality across large volumes of requests and diverse content formats.
In financial services, inference platforms enable real-time fraud detection, credit scoring, and algorithmic trading. These use cases depend on fast, deterministic responses and strict reliability. Inference platforms process streaming data, apply predictive models instantly, and operate within tight latency budgets where delayed or incorrect decisions can lead to financial loss.
Autonomous systems rely on inference platforms to process sensor data and make decisions in real time. Robotics, drones, and autonomous vehicles require low-latency inference at the edge to operate safely. Inference platforms enable local model execution, reduce reliance on cloud connectivity, and ensure predictable behaviour in dynamic, safety-critical environments.
Selecting an AI inference platform is rarely a one-size-fits-all decision. Debut Infotech helps businesses evaluate models, workloads, compliance requirements, and growth expectations before committing to infrastructure. As a top-tier enterprise AI development company, the focus stays on practical fit. Performance targets, cost behavior, security requirements, and future scalability are weighed together.
By translating technical trade-offs into clear business decisions, we enable teams to deploy inference platforms that support real products, real users, and long-term AI strategy without unnecessary complexity.
In 2026, the right AI inference platform can be a business differentiator—balancing performance, cost, scalability, and security. From real-time conversational systems to production-ready AI pipelines, inference infrastructure dictates user experience and operational efficiency.
By understanding core components, provider types, and business requirements, organizations can make informed decisions that align with both technical and strategic goals. Thoughtful platform selection minimizes risk and accelerates the return on AI investments.
A. Businesses use AI inference platforms to serve predictions at scale without breaking budgets. They help manage traffic spikes, reduce latency, and pick the right hardware. This matters for apps such as recommendations, fraud checks, chatbots, search, and computer vision, used daily by customers worldwide across industries.
A. Cloud AI services bundle training, storage, and tooling. An AI inference platform zooms in on running models efficiently after training. It provides finer control over latency, costs, model versions, and deployment targets such as CPUs, GPUs, edge devices, and specialized accelerators used in production systems worldwide.
A. The “best” AI inference platform depends on your goals. Key factors include latency requirements, model complexity, supported frameworks, and deployment targets. Cloud-based, edge-compatible, or hybrid platforms each excel in different scenarios. A platform that matches your workload while minimizing cost and maximizing performance is the right choice.
A. Yes, they often lower costs by optimizing resource use. Features like autoscaling, batching, and hardware-aware scheduling prevent wasted compute. Teams avoid paying for idle GPUs and can balance performance with budget, especially as usage grows and traffic becomes unpredictable across regions and time windows easily.
A. AI inference platforms work well for real-time predictions and high-volume batch jobs. Common workloads include recommendations, image and video analysis, speech recognition, fraud detection, and personalization. Basically, any application that needs fast, repeatable model predictions in production can run without the daily overhead of constant retraining or tuning.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com
Copyright © 2026, Debut Infotech. All rights reserved. | Privacy Policy


