ON THIS PAGE
Progress0%





Our Global Presence :

Large Language Models have crossed a threshold as they are not just restricted to research laboratories or chatbot experiments anymore. They are being directly integrated into the systems that enterprises are utilizing to operate their businesses. The question of whether a company is deciding between AI integration vs development as a more broad strategic question or whether you have already bet the chips on implementing LLM capabilities into core applications, the question of how to do it right, at scale, without introducing new risks remains the same.
At Debut Infotech, we have seen consistently that the difference between successful deployments and stalled ones comes down to architectural clarity and strategic planning — not technology selection alone.
This guide provides technical leaders, product managers and enterprise decision makers with a grounded understanding of what LLM integration actually looks like: from use cases and architecture to customization strategies, real challenges and implementation steps.
A Large Language Model (LLM) is a kind of Artificial Intelligence (AI) system that is trained on vast amounts of text to learn how to read, generate and think about human language. Large language models can do summarization, question answering, translation, code generation, categorization, and structured data extraction, without being expressly programmed to do each of these things.
Some of the most renowned LLM models include OpenAI’s GPT series, Anthropic’s Claude, Google’s Gemini and Meta’s LLaMA. Each has different performance characteristics, cost profiles, context window sizes, and licensing terms. These differences are of considerable importance for enterprises weighing up which models to work with, in terms of how an AI system integration is designed and what it can deliver.
The difference is not just model capability; it’s the infrastructure around it. APIs, orchestration frameworks, vector databases, and deployment tooling have matured so that the integration of LLMs is an engineering problem rather than a research challenge.
This is reflected in the numbers. McKinsey found organizations using generative AI across business functions rose from 33% in 2024 to 67% in 2025. According to Gartner, by 2026, 40% of enterprise applications will have embedded AI agents, compared to less than 5% in 2025.
It may be difficult to prioritize given the range of what LLMs are capable of. The best enterprise integrations don’t begin with the widest possible scope. They start with some specific, language-heavy workflows where the ROI is clear, and the complexity of AI system integration is manageable.
These use cases have consistently produced measurable results in enterprise contexts:
Customer service is the main use case for large language models (LLMs) in enterprises, as there is a high volume of text generated in support functions. Large language models are good at things like resolving queries at first touch, drafting responses, summarizing histories of interactions and routing complex cases accurately.
Enterprise knowledge is hidden in different places, like CRMs, ERPs, wikis, and communication platforms. The traditional keyword search does not provide the right information at the right time. LLMs connected to internal knowledge bases through RAG changes – employees can ask questions in natural language and receive answers grounded in up-to-date, verified internal content. The productivity improvements in knowledge-intensive jobs are substantial.
Enterprises have to deal with huge volumes of unstructured documents: contracts, filings, insurance claims, and procurement agreements. Traditionally, extracting structured information has been labor intensive or required expensive rule-based systems. LLMs do this with an accuracy and flexibility that previous approaches could not match, making it a high-value capability for financial services, legal, insurance and healthcare.
Software engineering teams are leveraging LLMs to code, review pull requests, document, explain legacy codebases, and generate unit tests. One of the most consistently reported outcomes of enterprise AI solutions is the improvement of developer workflows, with teams reporting 20–40% reductions in time spent on routine coding tasks.
LLMs can be used to translate natural language questions into database queries, to generate narrative summaries of structured datasets, and to produce draft reports from raw data. Business analysts no longer need to know SQL to query databases, thanks to natural language interfaces that provide access to data. What used to take days in reporting cycles can now be done in hours.
One of the first architectural decisions in any enterprise LLM integration is where the model itself will be deployed.
| Deployment Model | Description | Best For | Key Trade-offs |
| Public Cloud API | Use vendor-hosted model via API (OpenAI, Anthropic, Google) | Fast prototyping, standard use cases | Data leaves your infrastructure; vendor dependency |
| Private Cloud | Deploy open-source model in your own cloud environment | Regulated industries, sensitive data | Higher operational overhead; model management required |
| On-Premises | Run LLM entirely within your own data center | Maximum data control, air-gapped requirements | Highest infrastructure cost; requires GPU hardware |
| Hybrid | Mix of cloud API for non-sensitive tasks + on-prem for sensitive data | Complex enterprise environments | Most flexibility; more complex architecture to manage |
Understanding the components of an enterprise LLM integration at an architectural level helps demystify what the engineering work actually involves.
A typical enterprise LLM integration operates across five functional layers:
The API gateway pattern is the standard approach to managing model access for enterprises running multiple LLM applications across business units. A centralized gateway manages all LLM consumers in the organization, handling authentication, rate limiting, request routing, and cost attribution. This creates governance visibility and prevents individual teams from spinning up ungoverned AI integrations that create compliance or cost surprises.
Prompt engineering has matured from an informal art into a structured engineering discipline. Enterprises are building dedicated prompt management services that version, test, and deploy prompts across LLM endpoints. A prompt change is a system behavior change and deserves the same version control and deployment rigor as any other code change.
LLMs are powerful, out of the box, but they don’t know your business. Getting an LLM to perform at enterprise quality in a specific domain requires one or more customization strategies.
RAG ( Retrieval-Augmented Generation ) is a common way of customization in enterprise environments: it connects a language model to a retrieval system that is connected in real time to a vector database of internal documents. This approach collects related content based on user questions, ensuring that the answers are backed by current, specific data.
RAG can be deployed quickly, does not require model re-training, and provides source traceability for compliance sensitive applications. Output quality is directly dependent on knowledge base quality and curation, but it is still the highest value starting point before investing in more complex customization.
LLM fine-tuning involves taking a pre-trained model and continuing its training on a curated dataset of domain-specific examples. The model has learned your organization’s vocabulary and tone, document formats, and domain patterns beyond the capabilities of prompt engineering and retrieval. Fine-tuning works well for narrow tasks that have consistent input-output mappings and have enough high-quality training data.
Techniques like LoRA (Low-Rank Adaptation) have democratized and cheapened fine-tuning, but it is still a costlier and time-consuming route than RAG-based procedures.
AI agents leverage LLM capabilities for multi-step reasoning and action execution to support use cases including automated research, data reconciliation, code reviews, and customer journey orchestration. Gartner expects that by 2026, 40% of enterprise apps will include embedded AI agents. They introduce governance complexity requiring careful guardrail design, human-in-the-loop checkpoints, and rigorous monitoring.
For agents: require orchestration frameworks, tool registries, and state management layers to support the AI tech stack. This is not necessary for pure LLM integrations.
| Approach | Speed | Cost | Domain Specificity | Best Use Case |
| Prompt Engineering Only | Fastest | Lowest | Low | General tasks, broad language use cases |
| RAG | Fast | Low–Medium | Medium–High | Knowledge-grounded Q&A, document search |
| Fine-Tuning | Slow | Medium–High | High | Specialized tone, format, domain expertise |
| Agents | Medium | Medium–High | Variable | Multi-step automation, cross-system workflows |
| RAG + Fine-Tuning | Slow | High | Highest | Production-critical, accuracy-sensitive applications |
Security is not a bolt-on consideration for enterprise LLM integration — it is a foundational design requirement. LLM security architecture must be defined before deployment, not after.
Related Read: 10 Best Large Language Model Development Companies in the USA
An LLM integration in a production enterprise leverages a defined set of technologies across several functional categories. Grasping the stack helps organizations to make informed build vs. buy decisions and understand the technical dependencies of their integration projects.
| Stack Layer | Common Tools / Technologies |
| LLM Models | GPT-4, Claude, Gemini, LLaMA, Mistral, Falcon |
| Orchestration Frameworks | LangChain, LlamaIndex, Semantic Kernel, Haystack |
| Vector Databases | Pinecone, Weaviate, Chroma, Qdrant, pgvector |
| Embedding Models | OpenAI Ada, Cohere Embed, BGE, E5 |
| Deployment Infrastructure | AWS Bedrock, Azure OpenAI, Google Vertex AI, HuggingFace |
| Monitoring and Observability | LangSmith, Arize, Weights & Biases, custom dashboards |
| Security and Guardrails | NeMo Guardrails, Rebuff, custom input/output filters |
| API Management | Kong, AWS API Gateway, Azure APIM |
The selection of components for this stack is based on matching tools to your cloud environment, compliance requirements and engineering capabilities. Such experienced consulting partners can add value to your AI architecture design because they have experience integrating tools into a unified system ready for production.
The honest picture of enterprise LLM integration includes a set of recurring challenges that organizations consistently underestimate. Knowing them in advance makes planning more realistic and execution more effective.
Enterprise data is typically trapped in ERP platforms, antiquated CRMs, and proprietary systems that were never built for AI. In any LLM integration effort, the longest phase is often putting in place reliable connectors and transformation pipelines.
LLM output is only as reliable as the data feeding it. Years of inconsistently structured or poorly maintained data will produce output quality problems that model tuning cannot fix. Data readiness assessment is a prerequisite, not an afterthought.
LLMs generate plausible text without factual verification. In legal, medical, and financial contexts, this requires active mitigation through RAG grounding, validation pipelines, and human review checkpoints.
Token creation speed, retrieval latency and context window size all effect end to end response time. The model choice, caching techniques, and processing patterns should meet the latency tolerance of each individual use case.
Token-based pricing scales directly with usage volume. Without token monitoring and cost governance in place, budget overruns are common. Monthly costs for production systems typically range from $500 to $10,000+, and higher for heavy-traffic applications.
Regulated enterprises must demonstrate that AI systems operate within documented policies and produce auditable outputs. Building governance into the architecture from the start is far less expensive than retrofitting it after deployment. An AI automation strategy that does not include governance planning is incomplete.
A structured approach to enterprise LLM integration reduces the risk of the three most common failure modes: scope creep, underestimated infrastructure complexity, and insufficient testing before production exposure.
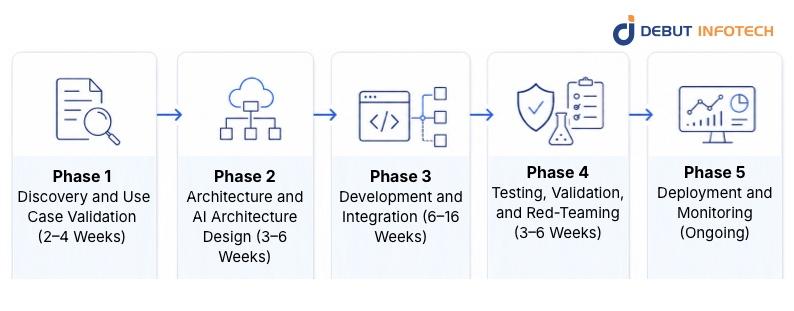
Define the specific problem the LLM will address. Map the current workflow in detail. Identify the data sources required and assess their quality and accessibility. Establish success criteria — not “the AI should be helpful” but measurable outcomes like accuracy thresholds, resolution rates, or processing time targets.
Select the AI deployment model (cloud, private, hybrid). Choose the base LLM models appropriate for the use case. Design the data pipeline from source to the LLM layer. Determine the customization approach (RAG, fine-tuning, or both). Define the security architecture, access controls, and governance framework. Produce the technical specification that will guide development.
Build the data connectors, preprocessing pipelines, and vector database. Implement the orchestration logic using appropriate AI frameworks. Develop the application layer interface. Integrate with existing enterprise systems like authentication, authorization, data sources, and downstream workflows. Conduct iterative testing at each integration point, not only at the end-to-end level.
Test for accuracy, latency, and cost at representative usage volumes. Conduct adversarial testing for prompt injection and data leakage vulnerabilities. Validate output quality across a diverse range of inputs, including edge cases. Confirm regulatory compliance documentation. Obtain sign-off from legal, security, and compliance stakeholders before any production exposure.
Deploy to production with monitoring instrumentation in place from day one. Track token consumption, response latency, error rates, output quality, and user feedback continuously. Establish a cadence for knowledge base updates, model performance reviews, and prompt version management.
| Project Type | Timeline | Indicative Cost |
| Simple API integration (chatbot, summarization) | 4–12 weeks | $30,000–$100,000 |
| RAG-based knowledge system | 8–20 weeks | $80,000–$300,000 |
| Fine-tuned domain model | 12–24 weeks | $150,000–$500,000 |
| Full enterprise LLM platform | 6–18 months | $400,000–$2,000,000+ |
The decision of which AI consulting company to work with for enterprise LLM integration deserves the same rigour as the technical decisions described above.
When evaluating AI consulting services and AI implementation services providers, look for evidence of the following:
Organizations that cannot build this capability internally are well-served by working with a dedicated generative AI development services firm as a long-term technical partner who understands their systems, their data, and their regulatory environment.
For organizations looking to hire generative AI developers with genuine enterprise delivery experience, the evaluation criteria above apply directly to individual practitioners as well as to firms.
Integrating large language models (LLMs) into enterprise applications is a complex task that requires careful architecture, disciplined data preparation, and comprehensive security planning. The AI trends indicate that LLMs will transition into foundational infrastructure for enterprises by 2026, offering advantages to those who implement them effectively now.
Debut Infotech provides a full-stack approach to LLM integration, assisting with architecture design, data readiness, production deployment, and ongoing optimization, while ensuring reliability in practical applications.
A. Integration connects a pre-trained or fine-tuned LLM to your existing data sources via API, usually combined with a RAG retrieval layer to ground responses in internal knowledge.
A. At minimum: an LLM provider (OpenAI, Anthropic, or open-source), an orchestration framework like LangChain or LlamaIndex, a vector database for retrieval, embedding models, an API gateway, and a monitoring platform. The right combination depends on your cloud environment, compliance requirements, and use case.
A. Simple API integrations typically run $30,000–$100,000. RAG-based systems range from $80,000–$300,000. Full enterprise platforms can reach $400,000–$2,000,000+. Ongoing costs — API fees, infrastructure, and maintenance — are separate and should be budgeted as a recurring operational expense.
A. The most common are legacy system connectivity, poor data quality, hallucination risk in accuracy-sensitive contexts, cost management at scale, and building compliance-ready governance frameworks. Underestimating any one of these is a frequent cause of delayed or over-budget projects.
A. Simple integrations can deploy in four to twelve weeks. RAG-based systems typically take eight to twenty weeks. Fine-tuning projects and full enterprise platforms run anywhere from twelve weeks to eighteen months. Data readiness is usually the biggest factor affecting the timeline.
A. RAG (Retrieval-Augmented Generation) connects an LLM to your internal knowledge — documents, databases, policies — so responses are grounded in your specific, current information rather than general training data. It is the most practical customization starting point for most enterprises because it delivers domain relevance without the cost of full model retraining.
A. Security is handled across multiple layers: prompt injection defenses, role-based access controls at the retrieval layer, PII filtering before responses are delivered, audit logging, and private or on-premises deployment for sensitive workloads. Building these controls into the architecture from the start is far less expensive than retrofitting them after deployment.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com
Copyright © 2026, Debut Infotech. All rights reserved. | Privacy Policy


