ON THIS PAGE
Progress0%





Our Global Presence :

Businesses are embracing AI at an unprecedented rate, but using the wrong customization approach can quickly turn a project into an expensive problem. That is why understanding RAG vs fine tuning is so important.
RAG and fine-tuning are not the same. RAG helps an AI system pull answers from trusted business sources such as internal documents, policies, product data, customer records, and knowledge bases. It’s particularly well suited for complex, sensitive, or frequently changing data.
Fine-tuning is about model behaviour. It can make the model respond in a particular tone, format, structure, or task, so it can be used for support workflows, classification, and brand-specific responses.
A wrong approach may lead to higher costs, out-dated or inaccurate responses, compliance issues, and delay deployment. The right method depends on your data, use case, security requirements, budget and accuracy needs.
This guide breaks down RAG vs fine
tuning clearly so enterprise teams can choose the best path for building reliable, scalable AI.
RAG, short for retrieval-augmented generation, is a way of helping an AI system answer questions with information from your own trusted business sources.
Instead of relying solely on the information the model already knows, RAG allows the system to search trusted company information first. This can be in the form of internal documents, PDFs, policy documents, CRM records, support tickets, product manuals, databases, knowledge bases, or web pages. Once it has identified information that is relevant, the AI will use this to generate a better answer.
Let’s look at an example of how this works:
For example, “What is our latest onboarding process for enterprise clients?”
It checks trusted sources such as internal policies, client documents, support files, or knowledge bases.
The system does not pull everything. It selects the information most likely to answer the question.
The model uses the retrieved information as context before producing an answer.
In a well-built system, users can see citations, document links, or source references so they can verify the response.
This is what makes RAG so useful for enterprise AI. It helps businesses build AI tools that are more accurate, current, and connected to real company knowledge.
However, RAG is not just about adding a vector database to an AI model. That is one of the biggest misunderstandings in enterprise AI projects. A strong RAG system depends on the quality of the entire setup, from how the data is prepared to how answers are monitored after deployment.
For example, if the company’s documents are outdated, duplicated, poorly labelled, or stored without proper permissions, the AI may retrieve the wrong information. If documents are broken into weak chunks, the model may lose important context. If access control is not properly designed, users may see sensitive information they should not access.
A reliable RAG architecture enterprise AI setup should include:
This is why enterprise RAG should be treated as a complete knowledge system, not just a quick AI feature. The model is important, but the surrounding architecture is what determines whether the answers are trustworthy, secure, and useful in real business situations.
For many enterprises, RAG is especially valuable because company knowledge changes often. Policies are updated. Product details change. Customer records evolve. Compliance requirements shift. With RAG, businesses can update their knowledge sources instead of retraining the entire model every time something changes.
That makes RAG a practical choice for organizations that need AI to work with private, current, and verifiable business information.
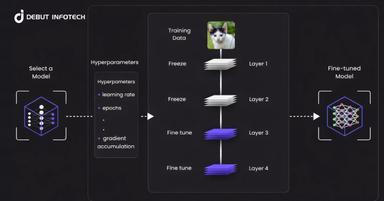
Fine-tuning is a way of teaching an existing AI model to perform a specific task more consistently. Instead of relying only on prompts, the model is trained with carefully prepared examples that show it the kind of responses your business expects.
In an enterprise setting, LLM fine tuning is especially useful when the goal is to improve the model’s behaviour, tone, format, or decision pattern. For instance, a company can fine-tune its model to ensure consistent responses to customers, to align to the tone of their brand, to classify legal documents, to help with medical coding, to categorise financial documents, to automate internal processes with fewer manual edits.
But, fine tuning is not the solution to all AI challenges. It does not keep the model up-to-date with your latest policies, product catalogues, price lists, compliance and regulations, or your knowledge base. That means if your company information changes often, fine-tuning alone can quickly become outdated.
This is where the difference matters. Fine-tuning helps the model act appropriately, while RAG helps the model find and use information appropriately. For businesses that need to handle rapidly evolving knowledge, RAG is the better option. But when the problem is consistency, structure or handling specialised tasks, fine-tuning is a great choice.
Understanding the enterprise problem is key to deciding whether to use RAG or fine-tuning. Do you need the model to be able to find the right information, or do you need it to be more predictable?
That is the real difference.
RAG is a good fit if your enterprise AI system needs to draw information from confidential, internal, or rapidly evolving information sources. Fine-tuning is best if you want the model to be more consistent with a certain tone, format, task patterns or workflows.
This table offers a side-by-side view for enterprise LLM optimization methods.
| Factor | RAG | Fine-Tuning |
| Best for | Accessing private, internal, or changing business knowledge | Improving model behaviour, response style, or task performance |
| Data freshness | Strong, because documents and indexes can be updated without retraining the model | Weaker, because updated knowledge may require new training data and retraining |
| Cost profile | Often more cost-effective when business knowledge changes often | Can become costly if the model needs frequent retraining |
| Hallucination control | Stronger when answers are grounded in approved sources and citations | Can improve consistency, but it does not fully remove hallucination risk |
| Compliance | Easier to audit because answers can be traced back to source documents | Harder to explain when knowledge is stored inside the model’s weights |
| Setup complexity | Requires clean data, retrieval pipelines, indexing, metadata, and access controls | Requires high-quality examples, training data preparation, and model evaluation |
| Best enterprise use case | Internal knowledge assistants, HR policy bots, legal document search, customer support knowledge systems | Ticket classification, structured outputs, brand voice, document tagging, and workflow automation |
| Transparency | Can show citations, source links, and document references | Less transparent unless supported by strong testing and monitoring |
| Maintenance | Update documents, indexes, permissions, and retrieval rules | Update datasets, retrain the model, and retest performance |
| Common mistake | Building RAG on messy data or weak retrieval logic | Fine-tuning when the real problem is missing or outdated knowledge |
In simple terms, RAG helps the model find the right information, while fine-tuning helps the model respond in the right way.
So, if your enterprise AI models need to respond to questions from evolving company information, RAG is typically the better choice. However, if the model already knows the information and needs to be more consistent, structured, in tone, or perform a task, fine-tuning could be more suitable.
For many established enterprise AI projects, the best solution is not strictly RAG or fine-tuning. It is often a hybrid approach, where RAG provides trusted knowledge access and fine-tuning improves how the model handles business-specific tasks.
An enterprise should use RAG when its AI system needs to give answers based on fresh, private, and verifiable business information.
This matters because many enterprise questions cannot be answered well using a model’s general knowledge alone. Employees might want answers to questions about internal policies, legal documents, HR manuals, product documentation, customer information, compliance documents, or technical manuals. In these scenarios, the AI needs timely access to information.
RAG is especially useful when company data changes often. Instead of retraining the model whenever a policy, document, or procedure is updated, RAG allows the AI to retrieve the latest approved information from connected sources when a user asks a question. This makes it a practical choice for businesses that need accuracy without constant model retraining.
It is also valuable when answers need to be checked. In high-risk or compliance settings, it’s not sufficient for the AI to provide a confident answer. Teams need to know where the answer is from, if it’s from an approved source and whether the user is permitted to access it. RAG can help with this by providing information from specific documents and, if necessary, citations.
RAG is a strong fit when:
For instance, consider a multinational company developing an AI assistant for HR, legal, IT and sales. Each team works with different documents, different policies, and different levels of access. HR policies may change monthly, legal documents may need strict approval, and IT support guides may be updated whenever systems change.
In this situation, RAG is often the better first choice. The system can retrieve only the documents each user is allowed to see, while keeping answers aligned with the latest approved information. If a policy changes, the business can update the source document instead of retraining the entire model.
That is why many organizations use knowledge systems using RAG to build enterprise AI tools that are more accurate, easier to govern, and better suited to real business environments.
Fine-tuning is best suited when the model needs to be more stable, predictable and consistent for a particular use case.
This is different from simply giving the model more information. If the primary issue is that the AI is not getting access to your company’s most updated documents, policies, or knowledge base, RAG might be more useful. However, if the model needs to adhere to a certain style, format, process or decision-making, fine-tuning might be more helpful.
You should consider fine-tuning when the model needs to:
This is why fine-tuning is often used as part of advanced LLM customization strategies. It allows you to control the way the model behaves, not only the information it has access to.
A financial services firm, for instance, might have an AI system that needs to categorise complaints in accordance with regulatory requirements. Here, it’s not only about retrieving information. The AI model needs to learn the company’s classification system, follow it consistently, and generate classifications that compliance professionals can audit.
Fine-tuning can assist as the model is exposed to well-curated data that demonstrates how the task should be done. Over time, this can increase consistency, save time and make the AI more valuable in practice.
However, fine-tuning is not something that should be done in a hurry. It requires high quality data that is well labelled and scrutinised by domain experts. If the data is not high quality, the model may learn wrong things. For businesses, fine-tuning should be complemented by testing, validation, monitoring, and human oversight to ensure it is safe to deploy.
In many enterprise AI projects, the strongest answer is not choosing RAG or fine-tuning. It is knowing when to use both together.
A hybrid approach makes sense when your AI system needs to provide accurate answers from trusted company data while also responding in a consistent, structured, and predictable way. This is one of the most practical enterprise LLM optimization methods, particularly if you’re concerned about accuracy, security, compliance or user trust.
So think of RAG as providing the model with good information, and fine-tuning as teaching the model how to use it.
RAG is helpful when the model requires updated, confidential, or source-backed information. This can be helpful for retrieving information from corporate policies, regulatory guidelines, product documentation, medical guidelines, legal templates, or customer knowledge bases. This can help avoid guesswork because the AI is referring to the right source, rather than just what it has been trained to know.
Fine-tuning can be helpful when you want the model to behave in a certain way. It can help the AI respond in a particular tone, use the same response format, use a business process or repeatedly perform a task in a consistent way.
For example, a healthcare organization may build an internal clinical policy assistant for staff. RAG can pull the latest approved policy before the AI answers a question. Fine-tuning can help the response follow the organization’s required format. Guardrails can prevent unsupported medical advice, while human review can be added for high-risk cases.
This is particularly important in industries like health, finance, insurance, and legal services, where an incorrect AI response can lead to significant risks. In these environments, businesses need more than speed. They need accuracy, traceability, governance, and clear accountability.
That’s why a combination of RAG and fine-tuning is often the best choice for enterprise AI. It provides trusted knowledge with predictable behaviour, which makes the system more valuable, secure and ready for enterprise use.
The decision between using RAG vs fine-tuning should not be purely a technical one. The decision impacts the cost of the system, the quality of the response, the security of sensitive information, and the safe deployment of AI throughout the enterprise.
Enterprises often get overly enthusiastic about a successful demo and rush to deploy. The problem with a demo is that it may not represent the real world scenarios. When employees begin to ask more complex questions, use confidential documents, or rely on the system to do their jobs, problems may emerge.
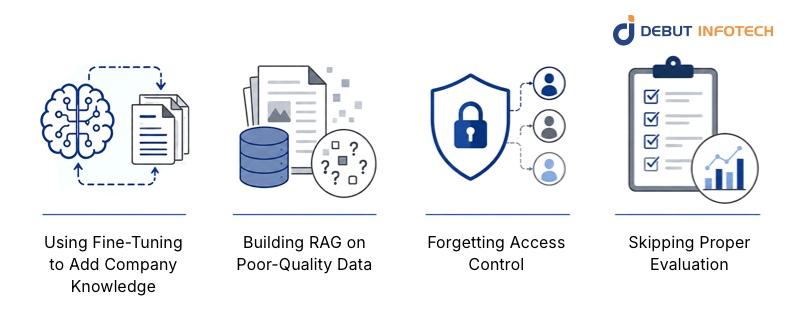
1. Using Fine-Tuning to Add Company Knowledge
A common mistake is fine-tuning a model simply because the business wants it to “know” internal information.
Fine-tuning can teach a model to respond in a particular style, format, or consistently carry out a task. However, it may not be the best way to regularly train the model to reflect company policies, product information, customer data, or business documents.
When that information changes often, RAG is usually the stronger option. It allows the AI to pull information from approved sources at the time of the query, instead of depending only on what has been built into the model.
2. Building RAG on Poor-Quality Data
RAG depends heavily on the quality of the information it retrieves.
If the company’s documents are outdated, duplicated, not properly labelled, not comprehensive, or spread out across a range of systems, then the AI’s responses may still be poor.
The system may retrieve the wrong information, fail to include relevant information, or use outdated information.
To build a RAG system, companies must clean, organise and manage their data. A strong AI experience starts with reliable information.
3. Forgetting Access Control
Security can become a serious problem if access control is not built into the retrieval layer.
A RAG system must only retrieve information the user has permission to view. If no access control is in place, an employee could view confidential HR data, corporate financial reports, legal documents, customer information, or other business documents.
That’s why access control is important to consider upfront. It should not be treated as something to fix after launch.
4. Skipping Proper Evaluation
An impressive demo can make a system look ready, but needs to be tested in production.
Many teams launch without clear test questions, accuracy benchmarks, hallucination tracking, retrieval checks, or user feedback. So they don’t know whether the system is actually helping, or just providing positive-sounding answers.
Effective LLM customization strategies should involve on-going evaluation. Businesses should track the quality of answers, relevance, hallucinations, user satisfaction, and business value.
The RAG vs fine tuning decision is not about choosing the most advanced technology. It is about choosing the approach that solves the right business problem.
RAG is often the better fit when enterprises need AI to access private, updated, and verifiable business knowledge. Fine-tuning is more suitable for changes to model behaviour, response format, speech style, or changes to specific tasks. In many scenarios, the best solution for enterprises is a combination of both.
At Debut Infotech, we assist enterprises with scaling AI solutions beyond experimentation to achieve business results. As a leading enterprise AI development company, we assist enterprises with AI strategy, data readiness assessment, secure architecture design, RAG implementation, fine-tuned model development, workflow automation, intelligent assistants, and enterprise AI integrations.
We prioritise developing AI solutions that are actionable, scalable, secure, and relevant to business needs. Whether you’re looking to automate manual tasks, improve processes, enhance customer service, or leverage internal data, Debut Infotech can help you decide which AI approach is right, and then build a real solution.
A. RAG helps an AI system find the right information. Fine-tuning helps it respond in the right way.
RAG retrieves data from approved business sources, such as internal documents, databases, and knowledge bases, at the time of a user’s query. It is useful when information is private, detailed, or regularly updated.
Fine-tuning trains a model with selected examples so it can follow a specific tone, format, process, or task more consistently.
In enterprise AI, RAG is best for improving knowledge accuracy, while fine-tuning is best for improving response consistency. Many businesses combine both for stronger results.
A. For most enterprise AI projects, RAG is the smarter place to start.
It lets AI pull answers from trusted business sources like policies, documents, and knowledge bases. This helps improve accuracy, keeps information easier to update, and gives teams more control over sensitive data.
Fine-tuning is better when the model needs to follow a specific tone, format, or workflow.
In short, choose RAG for knowledge, fine-tuning for behaviour, and a hybrid approach when you need both.
A. Enterprises should use RAG when an AI system needs reliable access to current internal information.
This includes policies, product documents, inventory data, pricing details, support content, or compliance guidelines.
RAG is usually a better fit than fine-tuning when the information changes often. It connects the LLM to approved data sources at the time of the query, making updates easier and improving answer traceability.
It can also reduce hallucinations by grounding responses in trusted business content.
Fine-tuning is better when the goal is to improve the model’s tone, format, behaviour, or task-specific performance.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com
Copyright © 2026, Debut Infotech. All rights reserved. | Privacy Policy