ON THIS PAGE
Progress0%





Our Global Presence :

Getting the right data at the right time has never been harder for businesses. Internal wikis get outdated, document repositories spread out over platforms, and employees spend hours hunting for solutions that are somewhere inside the organization but are essentially unreachable.
That’s precisely the problem that modern AI knowledge systems solve. And they achieve it with a mix of two core technologies: Retrieval-Augmented Generation (RAG) and vector databases. Debut Infotech builds production-grade AI knowledge systems for organizations concerned about making their internal data a competitive asset. In this article, we’ll cover exactly how these systems function, why the architecture matters, and what it takes to design one that delivers real benefits.
For technical teams and business leaders alike, an understanding of RAG and vector databases is no longer optional expertise. Businesses use these technologies to power AI document retrieval systems, robots, internal search tools, and customer-facing apps across almost every sector. Companies that know how to use their Large language models with their own data instead of against it are ahead of the rest.
Large Language Models are quite amazing. They know the background, generate fluent answers, and reason about complex themes. But they have a structural restriction that is very important in company environments: they only know what they were taught.
Training data is truncated. It doesn’t know anything about your company’s rules, secret procedures, customer information, or the new contract that your legal team completed last Thursday. Ask a normal LLM a question about your organization and it either guesses, refuses to answer, or makes up a confident-sounding answer based on unrelated general knowledge. All of these three consequences are difficult in production. As a consequence, RAG-based LLM knowledge base systems have become established as the de facto architecture for enterprises seeking AI founded in real organizational data.
That’s where enterprise knowledge retrieval AI changes the equation. The RAG system retrieves the most relevant documents depending on the user query. It then provides these documents as context to the LLM and asks the model to provide the answer based on them. The model reads the necessary bits in real-time, every time, without having to memorize your input.
There is also a compelling economic argument for this technique versus LLM fine-tuning. According to Morphik’s study, employing a RAG system with a 10,000-document enterprise knowledge base costs less than $100 if you use common embedding models. Fine-tuning a large model on the same domain information is $50,000 to $200,000 in computational resources and takes weeks to finish. And as your data updates, RAG systems refresh in hours. Fine-tuned models need another costly retraining session. RAG-based knowledge systems are the better choice for most business use cases, from both technical and financial perspectives.
Retrieval-augmented generation (RAG) is an architectural pattern that connects an LLM to an external knowledge source during inference.
The core workflow has four steps:

1. The query arrives. User asks a natural language question: “What is our refund policy for enterprise contracts signed prior to 2024?
2. The query is converted to a vector embedding. The query is then passed through an embedding model, which transforms the text into a high-dimensional numerical representation that encodes its semantic meaning.
3. The vector database performs a similarity search. The embedding is then evaluated against stored document embeddings, and the most semantically related chunks are obtained. This is semantic search with vector DB in action; the engine discovers relevant content based on meaning, not keyword overlap.
4. The LLM generates a grounded response. The original question and the retrieved fragments are fed into the LLM. It reads them and produces a response tied to those exact documents.
The end result is a system that can answer accurately and source-grounded, utilizing your genuine internal data, without delusion and without the need for the model to hold your whole knowledge base in its parameters. And that’s how artificial intelligence ultimately becomes truly useful inside a big business.
A vector database is a specialized infrastructure for storing, indexing, and searching high-dimensional vector embeddings at scale. That memory layer is what makes RAG operate.
Structured data is stored in rows and columns in traditional relational databases. They are great for exact-match lookups, but cannot do semantic similarity search. Searching for the keyword “employment termination policy” will not bring back a document called “Workforce Separation Guidelines,” even if the papers include the same information. A vector database overcomes this by matching the semantic meaning of the query to stored document embeddings, obtaining results based on conceptual similarity rather than lexical overlap.
The vector database AI architecture that enables commercial AI knowledge systems is based on approximate nearest neighbor (ANN) search. The most widely adopted indexing method for this purpose is HNSW (Hierarchical Navigable Small World), which enables sub-millisecond retrieval latency for millions of stored vectors. This speed allows for enterprise-scale real-time conversational AI systems.
The market shows how valuable that infrastructure has become. The global vector database market size was assessed at $2.65 billion in 2025 and is anticipated to reach $8.95 billion by 2030, increasing at a compound annual growth rate (CAGR) of 27.5%. That trajectory has been driven almost exclusively by enterprise adoption of RAG pipelines, semantic search apps, and LLM-powered solutions.
| Vector Database | Type | Best For | Hosting |
| Pinecone | Native, managed | Enterprise production deployments | Cloud (managed) |
| Weaviate | Native, open-source | Hybrid search, multi-modal data | Cloud or self-hosted |
| Qdrant | Native, open-source | High-performance, Rust-based | Cloud or self-hosted |
| pgvector | Extension (PostgreSQL) | Teams already running Postgres | Self-hosted |
| Chroma | Open-source | Development and smaller workloads | Self-hosted |
| Milvus | Open-source, distributed | Billion-scale vector workloads | Cloud or self-hosted |
You need more than a vector database and an LLM to build an AI knowledge system ready for production. It is a system of layers where the function of each layer is well defined, and the quality of each layer directly influences the quality of the output.
The value of a knowledge system is determined by the quality of data. The ingestion pipeline collects documents from multiple sources such as wikis, SharePoint, and ticketing systems. Raw documents have to be pre-processed to fix formatting, normalize encoding, remove duplication and extract clean text (particularly from PDFs or images using OCR).
This preprocessing is really important. If your data is badly cleaned, your embeddings will be ineffective, and that will lead to poor retrieval and poor replies.
Don’t store documents one by one in a vector database. It averages their significance and makes exact retrieval hard. Rather, they need to be broken down into smaller, more consistent pieces. The chunking approach also matters, as fixed-size chunking can break the material, whereas semantic chunking keeps the context and enhances retrieval accuracy. In addition, overlapping chunks can improve relevance by sharing content across boundaries.
An embedding model processes each chunk and converts it into a dense numerical vector. This vector preserves semantic meaning and influences retrieval quality. Commonly employed models in enterprise AI document retrieval systems are OpenAI’s text-embedding-3-large, Cohere’s embed-v3, and open-source models like BGE-large and nomic-embed-text.
Fine-tuning on relevant corpora can be helpful for domain-specific tasks, while multilingual environments can benefit from models such as Cohere’s multilingual-22-12 or LaBSE that maintain semantic meaning across languages.
Generated embeddings are stored in the vector database alongside the original text chunk and metadata. The metadata layer deserves attention. Tagging each chunk with its source document, creation date, department owner, access level, and document type enables filtered retrieval.
A query from the finance team can be restricted to finance department documents at the retrieval layer. This is how role-based access control is enforced in AI knowledge systems without requiring the LLM to make access decisions. The index structure determines retrieval speed.
When a user submits a query, the orchestration layer manages the retrieval and generation sequence. In a production-grade RAG pipeline architecture, this typically involves:
Query processing: Enhances retrieval coverage by rewriting or expanding user queries, using techniques such as HyDE, which generates hypothetical answers to improve document relevance.
Hybrid retrieval: Merges dense vector search with sparse keyword search methods such as BM25 or SPLADE, showing superior performance for enterprise knowledge retrieval AI when combining semantic and lexical precision.
Reranking: It uses a cross-encoder reranker to re-rank retrieved articles depending on their relevance to the original query. This reduces noise in the context and helps to improve the accuracy of results.
Generation: Re-rank document chunks and prepend the top chunks to the original query as context in the context window of the LLM. The system prompt informs the model to answer questions based on the retrieved context and reference sources. It also instructs the model to be upfront about the constraints of the retrieved context.
Enterprise RAG deployments handle sensitive organizational data. Security cannot be an afterthought. The critical controls include metadata filtering at the retrieval layer to enforce document-level access permissions, input validation to prevent prompt injection attacks, output filtering to detect and block PII leakage, and full audit logging of every query and response for compliance purposes.
The “one big bucket” approach to vector storage, where all organizational documents share a single index with no access controls, is a common architectural mistake. It creates the risk that a junior employee could query the system and retrieve compensation data, strategic plans, or other restricted information.
One of the most significant practical benefits of RAG-based knowledge systems over standalone LLMs is the reduction in hallucination.
This approach has been shown to enhance accuracy for enterprise-specific questions, with the system’s effectiveness relying on retrieval quality, making design decisions such as the chunking strategy and the embedding model selection crucial.
Production accuracy relies on an up-to-date knowledge base. A RAG system that retrieves outdated documents can provide confident but incorrect answers. Automated sync pipelines for re-indexing documents are essential for reliability. Teams that hire AI developers with RAG experience benefit from establishing strong ingestion pipelines early, avoiding the need to retrofit them later.
Understanding where these systems create measurable value helps with prioritization decisions. The following are the most common and highest-impact use cases across industries.
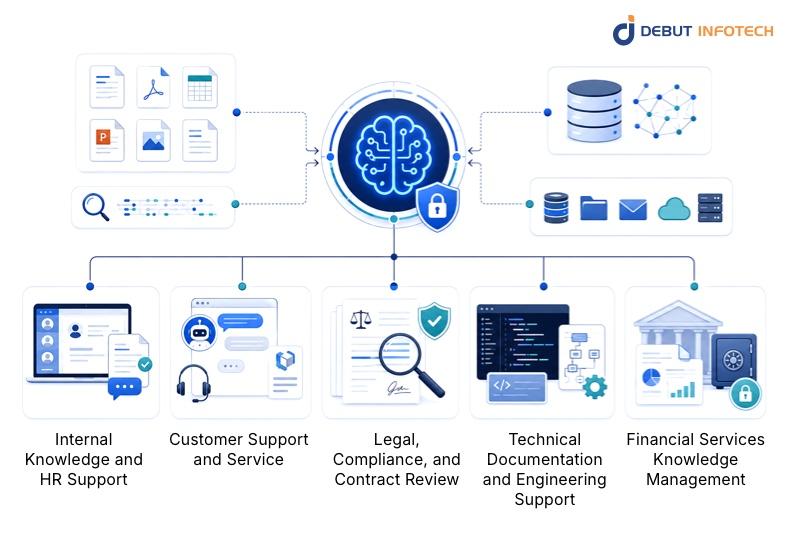
Organizations possess extensive policy documentation across various platforms. A RAG-powered AI knowledge system connected to these sources can instantly and accurately respond to employee queries, relieving HR teams from repetitive inquiries and providing consistent onboarding answers for new employees.
Customer-facing AI chatbots using RAG effectively retrieve information from product documentation and account data to address support queries autonomously. They outperform scripted chatbots by managing open-ended questions, synthesizing information from various sources for comprehensive answers, and indicating when human intervention is necessary.
RAG-powered systems are increasingly preferred in customer service for their reliability in high-stakes environments where accuracy is crucial to minimize risks of misinformation.
Legal teams use RAG-based AI document retrieval systems to search across contracts, regulatory documents, case precedents, and compliance materials. A query like “which vendor contracts include auto-renewal clauses with less than 30 days’ notice?” would require hours of manual search across a large contract database. A properly configured RAG system with well-structured chunking of contract documents surfaces the relevant clauses in seconds.
Engineering teams working across large codebases, technical specifications, and API documentation benefit from semantic search with vector DB backing. Queries phrased in natural language (“how does our authentication service handle token refresh for mobile clients?”) retrieve the relevant sections of technical documentation even when the terminology in the question does not exactly match the documentation wording.
Banks and investment firms use vector search enterprise AI for regulatory compliance lookup, product documentation retrieval, and internal policy search. Document-level access controls enforced at the retrieval layer make RAG architectures well-suited to financial services environments that require data segregation.
Teams evaluating how to build or procure an AI knowledge system face several architectural and operational decisions that determine long-term performance and cost.
Commercial platforms like Microsoft 365 Copilot, AWS Amazon Q, and Glean provide RAG-powered enterprise search for standard use cases, particularly for organizations within Microsoft or AWS ecosystems.
Custom AI development services are beneficial when dealing with proprietary data not suitable for these platforms, compliance issues preventing third-party data sharing, complex internal system integrations, or specific control needs over retrieval and generation.
The right embedding model depends on the nature of the content. Technical documentation benefits from code-aware models. Multilingual content requires multilingual embeddings.
Evaluating embedding models on a representative sample of your actual documents and queries before committing to production is standard practice in adaptive AI development. Benchmarks on generic datasets do not reliably predict performance on domain-specific enterprise content.
There is no universal correct chunking strategy. Short, structured documents such as FAQs and policy clauses often benefit from shorter chunks.
Iterative evaluation against real queries is how production teams arrive at the right configuration, which is why the AI tech stack for enterprise RAG systems includes evaluation frameworks alongside retrieval and generation components.
Deploying a RAG knowledge system is not a one-time event. Sustained accuracy and performance require ongoing operational practices.
This ongoing operational discipline is what the most experienced enterprise AI development teams build into their delivery methodology from the start, rather than leaving it as a post-launch consideration.
The enterprise knowledge problem persists as organizations generate more data than employees can search effectively, leading to mounting costs associated with not accessing the right information in a timely manner. AI knowledge systems using RAG and vector databases offer a proven solution by integrating Large language models with organizational knowledge, making it searchable and actionable.
Building such systems requires expertise in document processing, embedding model selection, vector database architecture, and security controls. Debut Infotech provides comprehensive AI development services for RAG-based knowledge systems, from data assessment and architecture design to production deployment and optimization, catering to both new and existing systems.
A. AI knowledge systems use RAG pipelines and vector databases to link Large Language Models (LLMs) with an organization’s internal data. When a user poses a question, the system creates a vector embedding, searches for similar document chunks, retrieves relevant content, and provides it to the LLM for context.
A. Cost varies based on scope, data volume, and complexity. Embedding a 10,000-document knowledge base costs under $100 in compute. Total development costs range from $30,000 to $150,000 for single-use-case systems and over $300,000 for complex multi-source deployments. Ongoing costs include API fees, database hosting, and MLOps maintenance. In contrast, LLM fine-tuning costs $50,000 to $200,000 in compute and requires expensive retraining with data changes.
A. Benefits include higher retrieval accuracy for natural language queries, reduced hallucination compared to standalone LLMs, source attribution for answers, role-based access control, and real-time updates.
A. A production RAG knowledge system needs: an embedding model (e.g., OpenAI text-embedding-3-large), a vector database (e.g., Pinecone), a RAG pipeline framework (e.g., LangChain), an LLM for answers (e.g., GPT-4o), a document ingestion pipeline, a reranking component, and an evaluation framework. The tech stack choice depends on data volume, latency, compliance, and self-hosting needs.
A. Accuracy relies on effective chunking strategies, quality embedding models, hybrid search methods, reranking processes, and automated re-indexing. Scalability depends on infrastructure choices, with distributed databases like Milvus and cloud services like Pinecone offering solutions. Maintaining accuracy involves continuous evaluation, query log analysis, and prompt tuning.
A. RAG retrieves relevant documents for LLM context without altering model parameters, while fine-tuning adjusts parameters with domain-specific data. RAG is often preferred for enterprise knowledge management due to its lower cost, real-time updates, document-level access control, and source attribution. Fine-tuning is better for adjusting model style or reasoning.
A. Single-source deployments can go live in 4-8 weeks, while multi-source enterprise deployments take 3-6 months. The main time investment is in data preparation. Hiring AI developers with RAG experience speeds up deployments and reduces accuracy issues. A phased approach, starting with one use case, is recommended.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
154 Eden Oak Trail, Kitchener, ON N2A 0H9
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com
Copyright © 2026, Debut Infotech. All rights reserved. | Privacy Policy


