ON THIS PAGE
Progress0%





Our Global Presence :

Machine learning depends completely on data as its basic fuel. Understanding what are the types of data in AI is critical, as these several forms of data such as facts, text, symbols, images, and videos exist in their raw state before processing begins. The transformation of raw data through processing operations produces information.
Without the required data, machine learning becomes an empty shell because mere programming code cannot achieve either intelligence or purpose. It is this data that allows machines to accomplish advanced tasks beyond what human imagination predicted.
Although the success of machine learning depends on data, machines lack a built-in ability to comprehend the meanings behind the data they process. They don’t understand why the letter ‘a’ looks the way it does, or why the word ‘this’ carries a particular meaning.
Similarly, most people eat food without truly understanding its nutritional breakdown or how it’s processed by the body, we simply eat because we need to. In the same way, machines “consume” data without comprehension. They lack the ability to interpret context or meaning from data.
They only identify patterns and correlations inside the data while neglecting to understand its fundamental nature. Data is to machines what fuel is to a car. It powers the system, but the car has no idea what fuel is or where it comes from.
At the end of the day, all machines really do is look for connections between pieces of data.This process is driven by the machine learning model, which deciphers correlations but never grasps context.
In this article, we’ll explore why data is so important in machine learning, and uncover why machines don’t actually understand the data itself but instead, focus on identifying relationships within it.
Without further ado let’s get started!
Machine learning (ML) and artificial intelligence (AI) reach peak performance by finding data patterns and using decision-making methods dependent on data. However, to achieve this, models require foundation knowledge of normal data patterns. The training data serves as an instructional background that enables models to understand newly introduced information.
Spam email detection serves as a practical example where ML models learn to identify this form of unwanted correspondence. Spam detection through ML models differs substantially from human instinct because these models require training to identify spam content. Training is essential for the identification of these spam contents. The training data consists of numerous labeled emails which include both spam content and authentic emails. Each email contains various features such as word choice, formatting, sender information, and presence of links or attachments.
Training data needs to be both comprehensive and varied emphasizing machine learning data quality to avoid biases or gaps. For spam detection, this could mean including emails from different industries, with different styles, tones, and structures. The data selection system needs to identify spam characteristics (eg. promotional language abuse and suspicious URLs) yet retain enough variety to include all forms of email communication.
Similarly, a ML model must initially analyze historical sensor data to understand patterns of machinery performance before it can identify equipment failure indicators in predictive maintenance. After training the model, it can detect irregular vibration signals as anomalies and simultaneously predict the replacement period of specific parts.
A model that completes model training and validation successfully and passes testing can be activated within real-world deployments. In the case of spam detection, a trained model can become part of email services to automatically sort out incoming junk messages while enhancing user experience and inbox hygiene. This integration highlights the role of Machine Learning in Business Intelligence, where data-driven decisions optimize operational efficiency.
Training a machine learning model involves a structured, repeatable workflow that ensures you get the most value from your data and your data science team’s time. Before jumping into the actual training, it’s important to:
Afterwards, you must choose applicable algorithms (considering distinctions like supervised learning vs unsupervised learning) and determine their hyperparameter settings and divide data into training and testing sections.
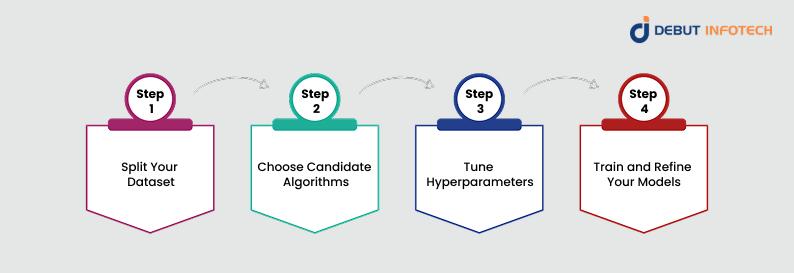
Step 1: Split Your Dataset
Your dataset functions as a constrained resource because you must use different data for training and testing your model. When testing models with the same data used for training there is a risk of misleading results because models might begin to memorize training data rather than learn the underlying correlations.
The standard process involves splitting data into three sections for training, validation and testing purposes. The model gets its training through data from the training set while the validation set optimizes its performance before evaluating its real-world capabilities through the test set.
One of the reliable approaches for data validation is named k-fold cross-validation. For instance, in 10-fold cross-validation:
This approach helps minimize overfitting and ensures a more reliable evaluation.
Step 2: Choose Candidate Algorithms
Machine learning algorithms do not operate with a uniform programming approach. Different types of models exist for various problems which include:
Selection criteria may include:
Step 3: Tune Hyperparameters
Hyperparameters function as guidelines to direct model learning because they do not originate from the training data. These parameters established prior to training commencement significantly shape how the model performs.
Examples:
Hyperparameter tuning can be done manually, through grid search, or using automated methods like random search or Bayesian optimization, addressing common machine learning challenges such as balancing performance and computational efficiency.
Step 4: Train and Refine Your Models
The next step involves model training now that you have chosen your algorithms alongside your defined hyperparameters. This involves:
The system operates similarly to athletics qualifying rounds where algorithms compete in separate setups until winners advance to the final competition.
1. Data Sources
The saying “garbage in, garbage out” rings especially true in the world of machine learning (ML). The success of an ML model strongly depends on the quality and comprehension of relevant diverse data used for learning. AI developers must select the right training data during their model development process as one of their main responsibilities.
Training data often isn’t readily available in perfect form. Although the adoption of precompiled datasets is on the rise yet the search for raw data continues to pose significant challenges. For example, establishing a model to identify distinct tree species demands substantial effort because obtaining thousands of picture samples from different seasons and perspectives would prove challenging.
Though there might be available raw data, it remains unfit for supervised learning unless it undergoes annotation processes. The model requires annotation to determine which patterns or features it should focus on. It requires precise and constant labeling because poorly labeled data tends to confuse the algorithm or reduce its training speed.
Some organizations build their own datasets by gathering and tagging data internally, but this can be costly and time-intensive. Alternatively, data could originate either from public repositories, academic datasets or crowdsourced platforms, underscoring the importance of knowing how to collect data for ml effectively. However, no matter where developers obtain their data, whether through internal efforts or partnerships with machine learning development companies, they need to guarantee its representative nature as well as its suitable structure for their project requirements.
2. Quality
High-quality data underpins model reliability. Bad prediction results frequently occur when there are common issues such as missing, incorrect entries and file corruption. This highlights the necessity of rigorous training data for machine learning models.
An example of such analysis exists in models examining customer review content. If many reviews are incomplete, written in different languages without translation, or full of typos, the model’s ability to detect sentiment will suffer.
The use of diverse datasets prevents bias while improving model generalization abilities. An ML system intended to detect human faces needs datasets featuring different ethnic backgrounds, ages, and lighting conditions; the dataset must include examples from all those categories.
3. Diversity and Bias
A dataset with predominantly adult male faces would create difficulties when identifying other facial types including female faces and children.
Data bias restricts model performance and reduces the achievements of fairness. For instance, a credit scoring model trained primarily on urban financial records might make flawed predictions for rural applicants. Diversity ensures the model doesn’t unfairly favor or overlook certain groups or scenarios.
4. Relevance
The training data should directly link to the problem which the model needs to address. If you’re building a system to detect phishing emails, using a dataset full of generic email conversations without any actual phishing examples would offer little value. Collaborating with machine learning development services can ensure datasets align with real-world threats and evolving attack patterns.
Relevance also ties into timeliness. An ML model which uses 2010 consumer data to make predictions will not work effectively today because shifts in consumer behavior and evolving technology have occurred since then. Up-to-date and context-specific data is vital.
The fundamental role of training data is to instruct AI systems with machine learning methods about how to detect patterns and generate decisions that solve problems. By exposing an ML model to data in machine learning, AI algorithms can learn the underlying structures and relationships within it. With its acquired understanding the model demonstrates accuracy in predicting outcomes or classifying unknown cases.
There are three primary approaches to training ML models:
1. Supervised Learning
In supervised learning, the data used for training is labeled with correct answers. For example, a model learning to identify spam emails requires training on messages that human experts have labeled as either “spam” or “not spam.” Experts from the human workforce take an essential part in designing and optimizing data sets which requires their input at multiple stages of training to enhance model performance.
2. Unsupervised Learning
Unsupervised learning requires the model to process unlabeled data thereby discovering natural patterns independently much like providing a student with unsolved puzzles to determine the rules by themselves. A common example is machine learning for customer segmentation in marketing, where a model clusters users into different groups based on behaviors without being told in advance what those groups should be.
3. Semi-Supervised Learning
This method blends the two previous techniques. The model is given a small amount of labeled training data for machine learning along with a larger set of unlabeled data, helping it learn efficiently with less human input. It’s often used in scenarios where labeling is expensive or time-consuming such as medical imaging, where a few X-rays are labeled by doctors and the model learns to interpret a larger dataset.
Every machine learning model needs data as its essential foundation to determine how models learn, behave, and perform in the real world. While advanced algorithms often receive the attention, they will never outperform their training data which determines their execution quality. The accurate development of models depends on data quality, quantity, and ethics in order to build trustworthy artificial intelligence systems. As machine learning continues to impact every facet of our lives, a deeper appreciation for the role of data and staying updated with machine learning trends will remain key to its full potential.
The training data must include the correct outcome, often referred to as the target or target variable. The machine learning algorithm analyzes the data to uncover patterns that link the input features to this target. Based on these patterns, it generates a model capable of making predictions for new, unseen data.
Data exists in various formats, but machine learning models typically work with four main types: numerical data, categorical data, time series data, and textual data.
A common rule of thumb suggests having a minimum of 10 training examples for each input feature or predictor in your model. So, if your model includes 10 features, you should aim for at least 100 labeled examples to ensure reliable training.
Machine learning and AI excel in two main areas: identifying patterns in data and making data-driven decisions. To carry out these tasks effectively, models require a reference point. Training data serves as this reference by setting a benchmark that allows models to evaluate and compare new data.
Training data in machine learning consists of labeled or annotated data used to “train” an algorithm or model, allowing it to learn how to perform a particular task and make precise predictions or decisions.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com
Copyright © 2026, Debut Infotech. All rights reserved. | Privacy Policy


