Between shifting market demands and growing data complexity, businesses aren’t just experimenting with machine learning anymore—they’re betting real budgets on it. And for good reason. According to McKinsey, 40% of enterprises using ML have already seen a 5%+ revenue lift.
That said, adoption doesn’t equal impact. A proof-of-concept is one thing—scaling ML into your ops stack is another. We’ve seen teams get stuck in pilot mode, overengineer what should’ve stayed simple, or misread model outputs because the business context wasn’t clear.
This guide walks you through the essentials: what is machine learning, the different types, what it actually delivers for enterprises, where it fits, what to watch out for, and how to approach it without second-guessing every decision. It’s not fluff. It’s what you’ll need to make machine learning work—for your team, and your bottom line.
A Brief History and Evolution of Machine Learning
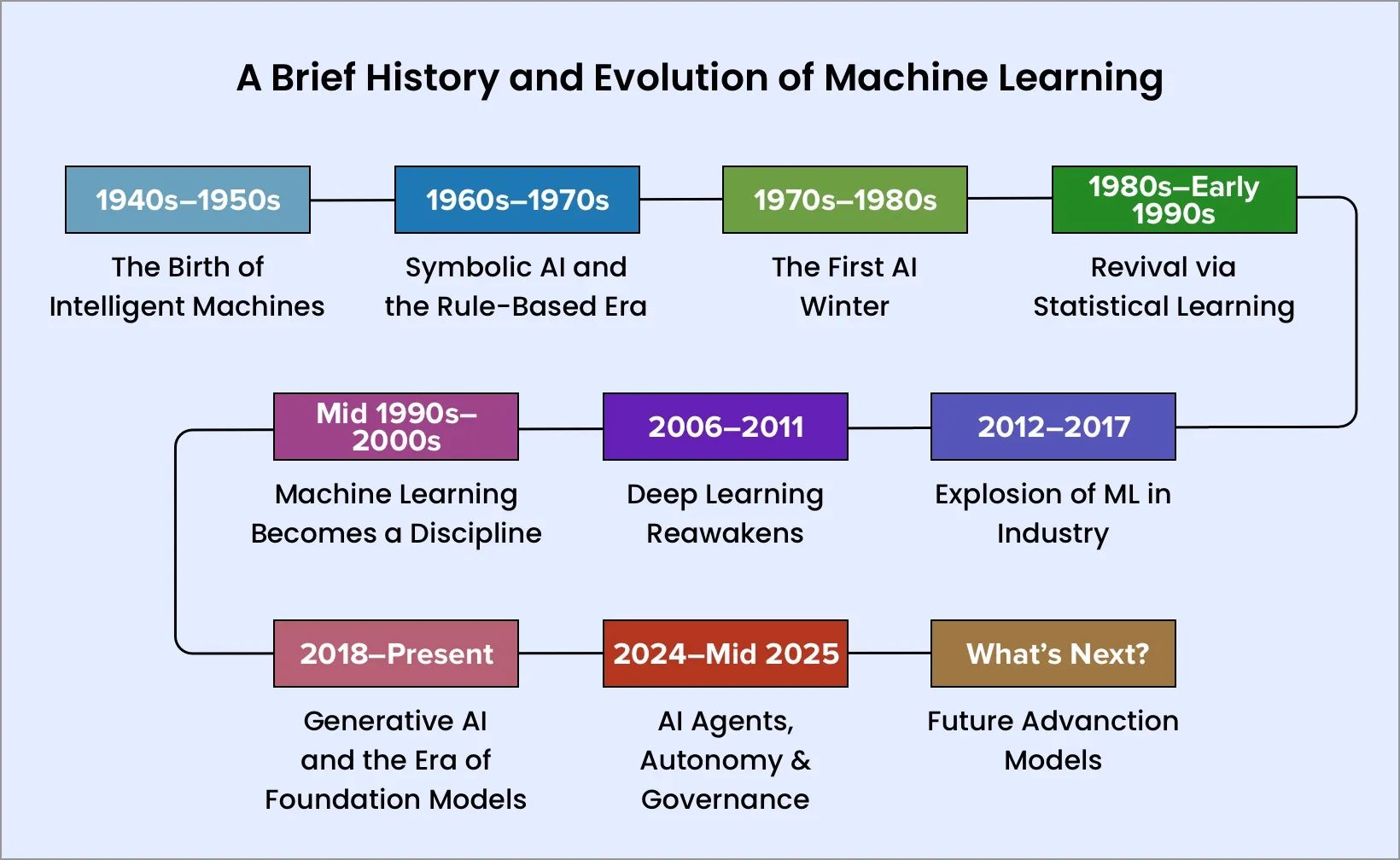
1. 1940s–1950s: The Birth of Intelligent Machines
- Alan Turing (1950): Turing’s seminal paper, “Computing Machinery and Intelligence,” proposed the idea of machines simulating any form of human intelligence. His introduction of the Turing Test laid the philosophical foundation for artificial intelligence.
- Early Neural Concepts (1943–1957):
In 1943, Warren McCulloch and Walter Pitts proposed a simplified mathematical model of the human neuron, laying the groundwork for artificial neural networks.
In 1957, Frank Rosenblatt developed the Perceptron, the first model capable of learning weights based on input data — a foundational element in supervised learning.
2. 1960s–1970s: Symbolic AI and the Rule-Based Era
- Symbolic AI: Researchers believed intelligence could be achieved by encoding all human knowledge and logic into rules. This led to expert systems like DENDRAL and MYCIN.
- Learning Limitations: While some early learning systems emerged (e.g., Samuel's checkers-playing program in 1959), computational power and data scarcity hindered machine learning’s growth. The field was dominated by hardcoded logic.
3. 1970s–1980s: The First AI Winter
- Perceptron Criticism: In 1969, Marvin Minsky and Seymour Papert published “Perceptrons,” highlighting its inability to solve non-linear problems like XOR. This criticism delayed neural network research for over a decade.
- Lack of Data & Hardware: The absence of large datasets and computational resources stalled data-driven learning approaches, leading to the first AI winter — a period of reduced interest and investment.
4. 1980s–Early 1990s: Revival via Statistical Learning
- Decision Trees and Inductive Learning: Algorithms like ID3 and CART allowed systems to infer rules from data in a tree structure, useful for classification tasks.
- Backpropagation (1986): A turning point. David Rumelhart, Geoffrey Hinton, and Ronald Williams introduced backpropagation for training multi-layer perceptrons (deep neural networks). This addressed previous limitations in training neural networks.
- Bayesian Networks: Judea Pearl’s work in probabilistic graphical models revolutionized machine reasoning under uncertainty — giving rise to algorithms that could learn from incomplete data.
5. Mid 1990s–2000s: Machine Learning Becomes a Discipline
- Support Vector Machines (SVMs) and Boosting: Algorithms like AdaBoost, SVM, and Random Forests dominated classification and regression tasks. They demonstrated high performance on real-world problems even with limited data.
- Shift to Data-Driven Approaches: Instead of hand-coded rules, models began learning directly from data. This made ML more practical for applications like spam filtering, fraud detection, and handwriting recognition.
- Rise of Open-Source Tools: Languages like Python and R gained popularity. Libraries such as Weka and LibSVM began to emerge.
6. 2006–2011: Deep Learning Reawakens
- “Deep Learning” Reintroduced: Geoffrey Hinton introduced the concept of “deep belief networks,” showing that deeper architectures could be pre-trained layer by layer and fine-tuned with supervised learning.
- GPU Revolution: The use of graphics processing units (GPUs) accelerated training of deep networks, making deep learning feasible for large-scale problems.
- ImageNet Challenge (2012): AlexNet, developed by Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever, won the ImageNet competition by a wide margin using a deep CNN. This proved the real-world superiority of deep learning and triggered an industry-wide shift.
7. 2012–2017: Explosion of ML in Industry
- Big Data & Cloud Integration: With vast digital data and cloud-based compute platforms, ML found applications in personalization, ad targeting, predictive maintenance, and more.
- Rise of Frameworks: TensorFlow (2015), PyTorch (2016), and Keras simplified deep learning model development.
- NLP Milestones: Models like Word2Vec, GloVe, and ELMo pushed forward the capabilities of language understanding.
- Reinforcement Learning Milestones:
AlphaGo (2016) by DeepMind beat the world’s Go champion using deep reinforcement learning.
This marked a symbolic victory and demonstrated the capability of combining search, deep learning, and RL.
8. 2018–Present: Generative AI and the Era of Foundation Models
- Transformers (2017): The introduction of the Transformer architecture by Vaswani et al. laid the foundation for language models like BERT, GPT, and T5.
- Pretrained Language Models (2018–2023):
BERT (2018) by Google changed the way search engines understood queries.
GPT-2 → GPT-3 → GPT-4 by OpenAI demonstrated large-scale generative capabilities, fueling a boom in content generation, summarization, and coding assistants.
- Multimodal and General-Purpose Models:
Models like CLIP, DALL·E, Gemini, and GPT-4 began combining language, vision, and other modalities.
These models are capable of reasoning, explaining, and generating across formats.
- AutoML, TinyML, Edge AI:
With widespread deployment came concerns about monitoring, fairness, bias, and compliance — giving rise to Explainable AI, ModelOps, and AI ethics frameworks.
9. 2024–Mid 2025: AI Agents, Autonomy & Governance
- 1. AI Agents Are Operationalizing AI Workflows
Systems like AutoGen, LangGraph, Crew AI, and Devin (Cognition Labs) go beyond Q&A to act as digital workers.
Agents can browse the internet, write and execute code, process documents, and collaborate with other agents — all in real-time.
- 2. Multimodal Reasoning Becomes Norm
Models now process text + image + audio + video inputs natively.
Use cases: Legal contract review (PDFs), customer calls (voice), internal docs (text), and UI analysis (screenshots) — all handled in one session.
- 3. Federated and Edge ML Matures
Apple, Google, and Meta scale on-device learning, enabling private, low-latency ML on phones, smartwatches, and IoT devices.
Federated models update without sending user data to the cloud — improving privacy by design.
- 4. Real-Time Fine-Tuning & Personalization
Companies like NVIDIA, OpenAI, and Mistral are working on real-time context adaptation and continual learning — where models evolve during use.
- 5. AI Governance & Regulation in Full Swing
EU AI Act (2024) is being implemented. Enterprises must classify models, ensure transparency, and maintain audit logs.
US and India are setting frameworks for model certification, model cards, and impact assessments.
- 6. Enterprise AI Strategies Mature
Organizations are appointing Chief AI Officers (CAIOs).
ML is now tied to business outcome KPIs: revenue acceleration, cost savings, efficiency per department.
10. What’s Next? (Mid-2025 and Beyond)
- Agentic AI ecosystems will form the backbone of digital workflows — automating everything from internal operations to customer support, finance, and HR.
- Domain-specific foundation models (for healthcare, law, fintech) will replace generic models in regulated industries.
- Hybrid Human-AI Teams will become the norm, blending ML agents and employees.
- Continual & lifelong learning models will adapt without retraining from scratch — mimicking human learning.
- Expect acceleration in quantum-assisted ML, neuromorphic computing, and AI-native infrastructure.
What is Machine Learning?
Core Types of Machine Learning
| Learning Type | Key Use Cases | Common Industries | Data Requirements | Example Models/Tools |
|---|---|---|---|---|
| Supervised Learning | Spam filtering, risk scoring | Finance, Healthcare, Marketing | Labeled datasets | XGBoost, SVM |
| Unsupervised Learning | Unsupervised Learning | Cybersecurity, Retail, Telecom | Unlabeled datasets | K-Means, PCA |
| Semi-Supervised | Document tagging, fraud detection | Banking, NLP, Medical Imaging | Labeled + large unlabeled data | Graph Neural Nets, VAEs |
| Reinforcement Learning | Game agents, robotics | Robotics, Gaming, AdTech | Interaction with environment | DQN, PPO, AlphaZero |
| Self-Supervised | Language models, image embedding | Legal, SaaS, Search Engines | Massive unstructured raw data | BERT, GPT, CLIP |
1. Supervised Learning
- Classification: Used when the output variable is categorical. Examples include spam detection (spam or not), sentiment analysis (positive, negative, neutral), and disease prediction (yes/no).
- Regression: Used when the output variable is continuous. Examples include house price prediction, stock price forecasting, and energy demand estimation.
- Common Algorithms:
Linear Regression
Logistic Regression
Support Vector Machines (SVM)
Decision Trees and Random Forest
Gradient Boosting
Artificial Neural Networks
- Real-World Applications:
Email spam detection
Credit scoring and loan risk prediction
Customer churn prediction
Fraud detection in finance
Diagnostic imaging in healthcare
- Benefits:
Straightforward to interpret and deploy
High accuracy when enough labeled data is available
Excellent generalization on real-world business data
- Limitations:
Requires extensive labeled datasets, which can be time-consuming and expensive to prepare
Prone to overfitting if not validated properly (requires techniques like cross-validation, regularization, or early stopping)
2. Unsupervised Learning
- Clustering: Automatically groups data points into clusters based on feature similarity. Common algorithms include K-Means, DBSCAN, and Hierarchical Clustering.
- Dimensionality Reduction: Reduces the number of input variables or features while retaining the most significant variance. Techniques like Principal Component Analysis (PCA), t-SNE, and Autoencoders help visualize high-dimensional datasets.
- Common Use Cases:
Customer segmentation for targeted marketing
Anomaly detection in cybersecurity and banking
Topic modeling in natural language processing
Grouping similar products or content recommendations
Pattern recognition in manufacturing or quality control
- Key Concepts:
Distance Metrics (Euclidean, Cosine, Manhattan)
Silhouette Score (to evaluate clustering)
Feature Space visualization for interpretatio
- Benefits:
Requires no manual labeling, making it cost-effective
Useful for discovering unknown insights or structures in large datasets
Scales well for early-stage exploratory analytics
- Limitations:
Evaluation is less objective (no ground truth labels)
Results are sensitive to data scaling, outliers, and initialization
Can lead to misleading clusters if not properly tuned
3. Semi-Supervised Learning
- Techniques:
Self-Training: The model learns from labeled data, then predicts labels on the unlabeled data and re-trains.
Co-Training: Two separate models are trained on different views of the same data and teach each other.
Generative Models: Models like Variational Autoencoders (VAEs) generate data that closely resembles the input distribution.
Graph-Based Learning: Uses similarity graphs to propagate labels across connected data points.
- Common Use Cases:
Medical image classification (e.g., cancer detection)
Speech recognition and transcription (partially labeled audio)
Document classification in legal or enterprise settings
Fraud detection with few labeled fraud cases
- Benefits:
Cost-efficient way to leverage large datasets
Increases model performance with limited supervision
Often outperforms purely supervised learning in low-label environments
- Limitations:
Model accuracy can deteriorate if pseudo-labels from unlabeled data are noisy
More complex to implement and monitor than supervised approaches
4. Reinforcement Learning
- Key Concepts:
Agent: The decision-maker (e.g., robot, bot)
Environment: Everything the agent interacts with
State: Current condition or situation
Action: What the agent can do
Reward: Feedback received for the action
Policy: Strategy the agent follows
Value Function: Expected long-term reward from a state
- Common Algorithms:
Q-Learning
Deep Q-Networks (DQN)
Policy Gradient Methods
Proximal Policy Optimization (PPO)
Actor-Critic Models
- Applications:
Game playing (e.g., AlphaGo, Dota2 bots)
Robotics and autonomous navigation
Real-time pricing in e-commerce
Portfolio management in finance
Smart traffic signal optimization
- Benefits:
Learns optimal strategies over time
Excels in dynamic, interactive environments
Capable of handling complex control problems
- Limitations:
Requires high computational resources
Needs exploration strategies and environment simulators
Often unstable during early training
5. Self-Supervised Learning
- How It Works:
In language models (e.g., BERT), words are masked and the model learns to predict them (masked language modeling).
In vision models (e.g., SimCLR), different augmentations of the same image are used to train models to identify representations that remain consistent.
- Use Cases:
Natural language understanding (sentiment analysis, Q&A)
Code completion and generation
Image-text alignment (vision-language models)
Legal document summarization
Voice and video understanding in media tech
- Common Techniques:
Contrastive Learning (e.g., SimCLR, MoCo)
Masked Autoencoding (e.g., MAE)
Multimodal Pretraining (e.g., CLIP, Flamingo)
- Benefits:
Eliminates the need for labeled data
Produces highly generalizable features
Forms the backbone of large language and vision models
- Limitations:
Pretext task design is crucial and non-trivial
Requires massive datasets and compute resources for training
Fine-tuning still needed for specific tasks
How Does Machine Learning Work (Step-by-Step Breakdown)
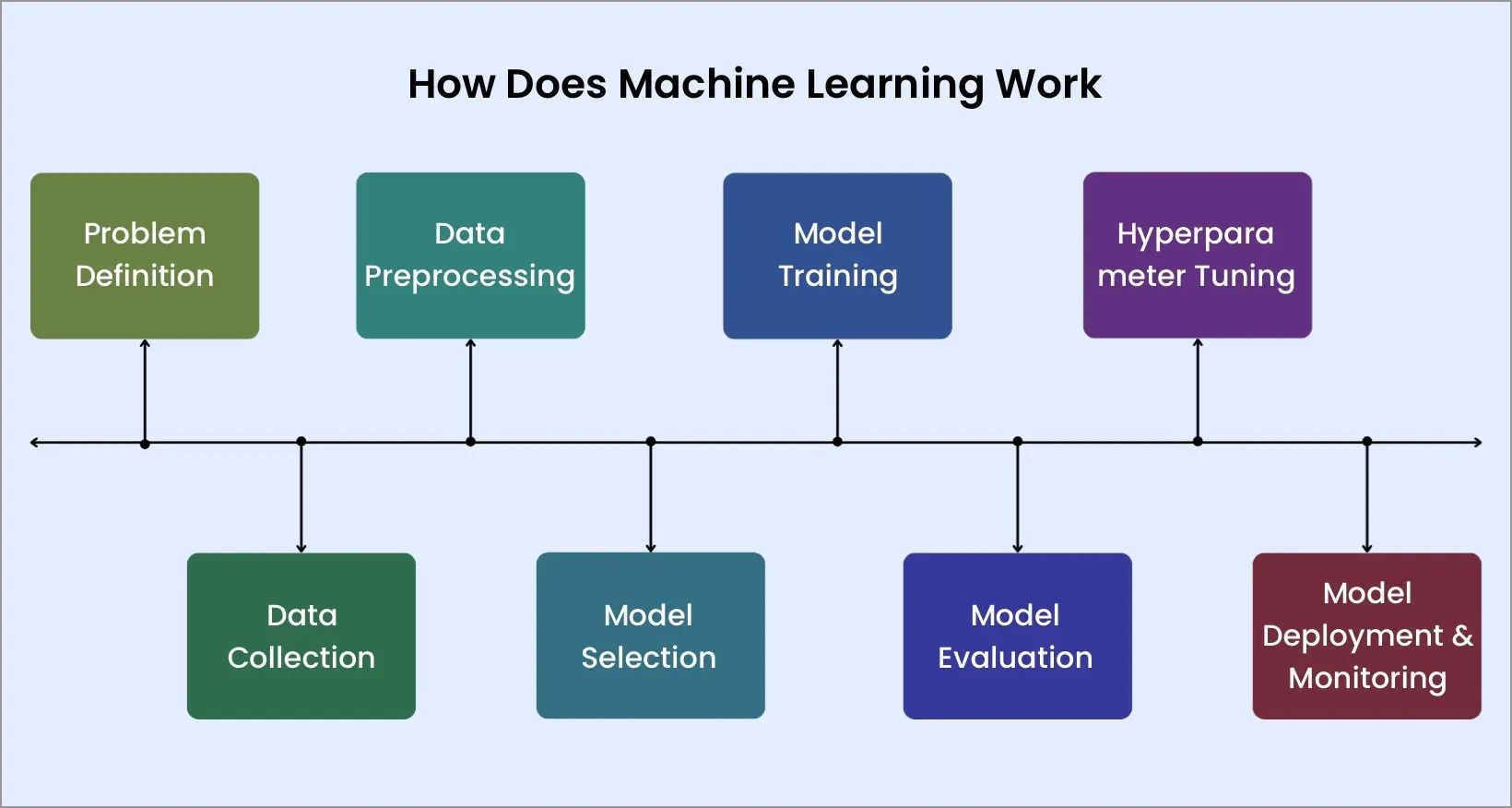
1. Problem Definition
- Key Focus Areas:
Determine the ML type: Supervised, Unsupervised, RL, or Self-Supervised
Define business objectives and performance metrics (e.g., accuracy, precision, ROI)
Identify whether the task is classification, regression, clustering, or ranking
Outline input features (X) and desired outputs (Y)
Clarify constraints, dependencies, and real-world usage
2. Data Collection
- Key Focus Areas:
Collect data from internal systems, third-party APIs, or public datasets
Capture both input features and output labels (if supervised learning)
Ensure data coverage across use-case scenarios
Address compliance: GDPR, HIPAA, CCPA, etc.
Structure raw data in usable formats (CSV, JSON, Parquet)
3. Data Preprocessing
- Key Focus Areas:
Handle missing values, outliers, and duplicates
Encode categorical variables (Label Encoding, One-Hot)
Normalize/standardize numerical features
Perform dimensionality reduction if needed (e.g., PCA)
Engineer new features to enhance predictive power
4. Model Selection
- Key Focus Areas:
Choose between algorithms: Decision Trees, SVM, Random Forest, XGBoost, Neural Nets
Match model type to task complexity and data volume
Ensure explainability vs accuracy trade-off (e.g., tree-based vs deep learning)
Use libraries like Scikit-learn, TensorFlow, PyTorch for implementation
Set baseline performance using simple models (e.g., Logistic Regression)
5. Model Training
- Key Focus Areas:
Choose appropriate loss functions (Cross-Entropy, MSE, Hinge)
Apply optimizers like SGD, Adam, or RMSprop
Split data into training, validation, and test sets
Incorporate regularization (L1, L2) to prevent overfitting
Monitor convergence across epochs and iterations
6. Model Evaluation
- Key Focus Areas:
Use classification metrics: Accuracy, Precision, Recall, F1, ROC-AUC
Use regression metrics: MAE, RMSE, R² Sco
Validate with k-fold cross-validation or bootstrapping
Visualize results using confusion matrix or error histograms
Evaluate alignment with business KPIs and stakeholder expectations
7. Hyperparameter Tuning
- Key Focus Areas:
Tune hyperparameters like learning rate, max depth, batch size, etc.
Use methods: Grid Search, Random Search, Bayesian Optimization Automate tuning with AutoML platforms (e.g., Google Vertex AI, Azure AutoML)
Monitor overfitting while tuning by tracking validation loss
Use frameworks like Optuna, Ray Tune, or Scikit-learn’s GridSearchCV
8. Model Deployment & Monitoring
- Key Focus Areas:
Deploy models via REST APIs, Docker containers, or cloud-based endpoints
Integrate with business systems or user-facing apps
Monitor drift (data & concept), prediction latency, and system load
Set up feedback loops for continual learning and re-training
Leverage MLOps tools (MLflow, SageMaker, Vertex AI, Kubeflow)
Key Characteristics and Capabilities of Machine Learning
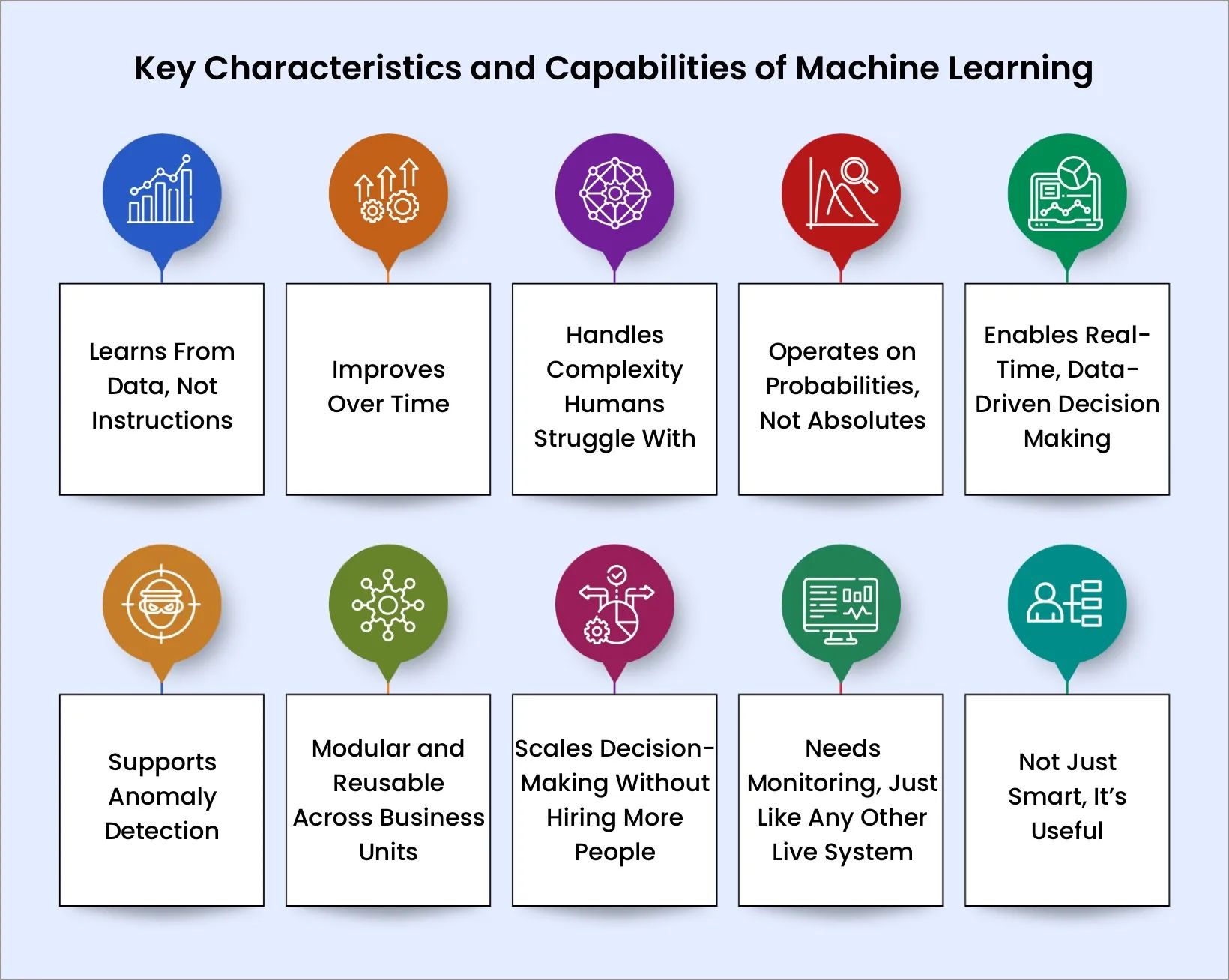
1. It Learns From Data, Not Instructions
2. It Improves Over Time
3. It Handles Complexity Humans Struggle With
4. It Operates on Probabilities, Not Absolutes
5. It Enables Real-Time, Data-Driven Decision Making
6. It Supports Anomaly Detection (Even When You Can’t Define "Weird")
7. It’s Modular and Reusable Across Business Units
8. It Scales Decision-Making Without Hiring More People
9. It Needs Monitoring, Just Like Any Other Live System
10. It’s Not Just Smart, It’s Useful
ML vs AI vs DL vs Data Science: Understanding the Differences (and Why They Matter)
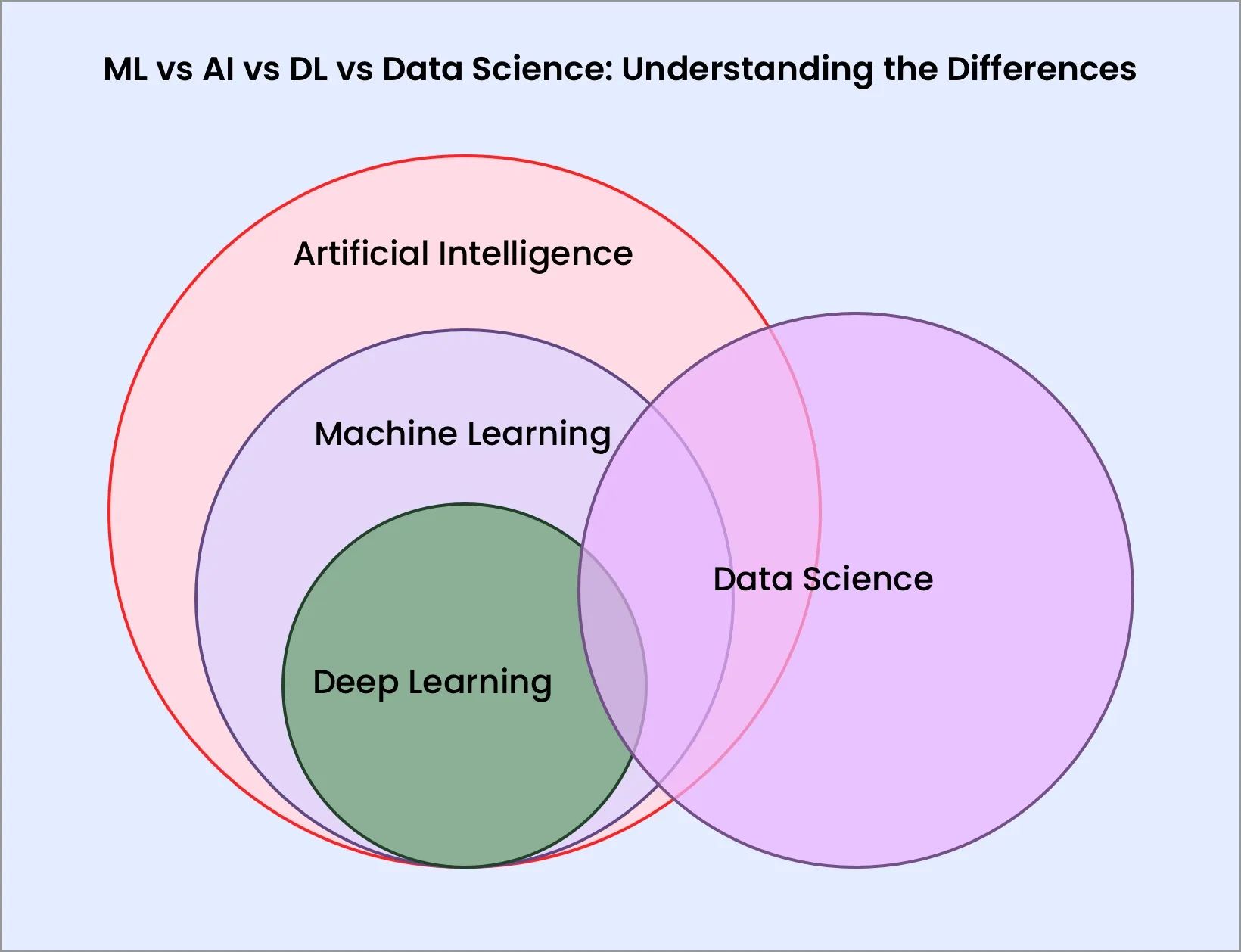
Artificial Intelligence (AI): The Big Picture
Machine Learning (ML): The Brains That Learn
Deep Learning (DL): The Neural Network Expert
Data Science: The Problem-Solving Discipline
So, How Does This Play Out in Business?
Common Machine Learning Algorithms and When to Use Them
1. Regression Models: Linear & Logistic
- Linear Regression predicts continuous numerical values by modeling a straight-line relationship between inputs and output using the equation: Y = β₀ + β₁X₁ + β₂X₂ + … + βₙXₙ + ε
- Logistic Regression is used for binary classification problems. Instead of predicting a value, it predicts the probability of a binary outcome using the sigmoid function. It maps outputs between 0 and 1, making it ideal for tasks like yes/no predictions.
- Linear: House price prediction, energy demand forecasting, revenue forecasting
- Logistic: Email spam detection, lead qualification, fraud prediction, disease diagnosis
- When you need interpretable models (e.g., feature importance via coefficients)
- When relationships between variables are linear or nearly linear
- When the dataset is tabular, clean, and not very large
- Poor performance on non-linear problems
- Assumes independence between features (especially for Logistic)
- Sensitive to outliers
2. Decision Trees & Random Forests
- Credit risk scoring
- Employee attrition prediction
- Fraud detection in transactional data
- Customer segmentation for campaign targeting
- When explainability is required (Decision Trees)
- When you want robust, generalizable models on tabular data (Random Forests)
- When you want feature ranking for exploratory analysis
- Decision Trees are prone to overfitting on small datasets
- Random Forests sacrifice interpretability for accuracy
- Not ideal for sparse or high-dimensional data (like NLP)
3. K-Nearest Neighbors (KNN) & Support Vector Machines (SVM)
- KNN: Pattern recognition, handwritten digit classification, recommender systems
- SVM: Email classification, sentiment analysis, facial expression detection
- KNN: Small, low-dimensional datasets where interpretability is not crucial
- SVM: High-dimensional spaces like text or gene expression data
- When you need precise decision boundaries
- KNN is slow at prediction time (computationally expensive at inference)
- SVMs don’t scale well with very large datasets
- Sensitive to feature scaling — preprocessing is essential
4. Clustering Algorithms: K-Means & DBSCAN
- K-Means partitions data into K clusters by minimizing the intra-cluster variance. It assumes spherical clusters and equal density.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise) identifies clusters based on data density, which allows it to detect arbitrary-shaped clusters and outliers.
- Customer segmentation in eCommerce
- Market basket analysis
- Outlier detection in security logs
- Social network analysis
- K-Means: When you have a general idea of the number of clusters
- DBSCAN: When clusters are non-spherical or contain outliers
- When your goal is exploratory analysis or unsupervised segmentation
- K-Means struggles with non-globular clusters and noise
- DBSCAN is sensitive to ε and not ideal for high-dimensional data
- Both require feature scaling for accurate results
5. Naïve Bayes & XGBoost
- Naïve Bayes: Sentiment analysis, spam filtering, topic classification
- XGBoost: Fraud detection, churn prediction, ad click-through rate prediction
- Naïve Bayes: High-dimensional, sparse datasets (NLP, text)
- XGBoost: Structured data, large tabular datasets
- When you need speed and high accuracy
- Naïve Bayes assumes feature independence (may not generalize well)
- XGBoost can overfit if not properly tuned
- Computationally more intensive than simpler models
6. Deep Learning: CNNs, RNNs, GANs, Transformers
- CNNs: Specialize in image and video processing.
- RNNs: Designed for sequential data like time series and text.
- GANs: Consist of a Generator and Discriminator in competition — used to generate synthetic data.
- Transformers: Use self-attention to process sequences in parallel, outperforming RNNs in NLP tasks and enabling large language models (LLMs) like GPT and BERT.
- CNNs: Face recognition, medical imaging
- RNNs: Language translation, stock forecasting
- GANs: Deepfakes, data augmentation
- Transformers: Chatbots, search engines, summarization
- CNNs: Visual and spatial pattern detection
- RNNs: When sequence and temporal relationships matter
- GANs: When labeled data is scarce and synthetic data is useful
- Transformers: High-performance NLP or multimodal tasks
- Requires large datasets and compute power (especially Transformers)
- Prone to overfitting if not regularized
- Opaque and difficult to interpret (“black box” models)
ML Development Environments & Tools: What Businesses Actually Use to Build Smart Systems
Programming Languages: Python Still Leads, But It’s Not Alone
- Python: The go-to for most ML tasks—data cleaning, model training, deployment, you name it. Libraries like NumPy, Pandas, and scikit-learn make it easy to get started. Plus, it plays nicely with TensorFlow, PyTorch, and Keras. If your team’s doing ML, odds are Python’s already in the mix.
- R: Great for statistical modeling and data visualization. It’s still widely used in academic research and by analysts who want deep insights into datasets—especially in fields like bioinformatics or social sciences.
- Julia: A bit of a niche player, but worth mentioning. Julia combines the speed of C with Python-like simplicity. Some teams exploring high-performance computing or numerical simulations have started experimenting with it, though adoption is still relatively small.
Frameworks: The Brains Behind Your Models
- Scikit-learn: Lightweight, fast, and perfect for classical ML—think regression, decision trees, clustering, and so on. It’s not built for deep learning, but it shines when your models don’t need neural networks. Great for quick prototypes and educational work.
- TensorFlow: Developed by Google, this framework is powerful, flexible, and scalable. It’s a bit verbose out of the box, but TensorFlow 2.x is way more user-friendly than earlier versions. If you’re working on production-grade deep learning, especially across devices, it’s a solid choice.
- Keras: Technically part of TensorFlow now, Keras is a high-level API that simplifies building and training deep learning models. It’s perfect for folks who want to skip boilerplate and just get to training models quickly.
- PyTorch: Created by Facebook, PyTorch is super popular among researchers and ML engineers who want more flexibility than Keras offers. It’s Pythonic, intuitive, and has grown into a favorite for experimentation and production use.
Cloud Platforms: No More Spinning Up Your Own GPU Cluster
- AWS SageMaker: Amazon’s ML platform offers end-to-end support—data labeling, model training, deployment, monitoring. It’s ideal for teams already deep into the AWS ecosystem. A bit steep for smaller teams, but very scalable.
- Azure ML: Microsoft’s take on ML-as-a-Service. It comes with AutoML, pipelines, and MLOps baked in. It’s tightly integrated with other Microsoft tools, which makes life easier if your enterprise already lives in Office and Azure.
- Google Cloud Vertex AI: Google’s platform is arguably the most forward-thinking in terms of model experimentation and orchestration. It supports AutoML, custom model training, and hyperparameter tuning—all from the same dashboard.
Data Annotation & Versioning Tools: Keeping Things Organized (And Legal)
- Labelbox, Scale AI, and SuperAnnotate: These tools help teams label images, video, text, and more. Many offer automation or “labeler marketplaces” to speed things up. If your model performance depends heavily on human labeling, these platforms can save a ton of time (and budget).
- DVC (Data Version Control): Like Git for data. It helps you version datasets, models, and pipelines. When combined with tools like GitHub, it makes ML projects feel more like standard software development, which is always a plus when collaborating across teams.
- Weights & Biases, MLflow: These tools help track experiments, log metrics, visualize training results, and manage model lifecycles. They're especially useful in teams where reproducibility is key—or where you’re testing 10 things at once and losing track fast.
Notebook Environments: Where Ideas Get Prototyped
- Jupyter Notebooks: The classic. Local or cloud-hosted, Jupyter is the go-to for most data scientists and ML practitioners. It works with Python, R, Julia, and more.
- Google Colab: Jupyter, but in the cloud—and with free GPUs. It’s a great choice for fast experiments or team collaboration. You don’t need to install anything, and you can share links just like a Google Doc.
- Deepnote, Kaggle Notebooks, and Microsoft Azure Notebooks: These are newer platforms offering real-time collaboration, version control, and more cloud-native features. They’re worth a look if your team is remote or you’re doing live demos often.
Want help choosing the right tools for your ML workflow?
Let’s chat—we’ll help you build a stack that fits your goals without the tech bloat.
Model Evaluation & Performance Tuning — Making Machine Learning Work Like It’s Supposed To
Cross-Validation: Your First Line of Defense Against Overconfidence
- Reduce the chance that your “great results” are just a fluke.
- Get a more realistic estimate of how your model might perform on new, unseen data.
- Catch early signs of overfitting.
Feature Importance and SHAP: Why Did the Model Do That?
- Understand what the model “thinks” is important.
- Detect any weird or unintended patterns (like postal codes influencing loan decisions).
- Improve or trim your model by focusing on the strongest features.
The Confusion Matrix: Still Underrated and Still Incredibly Useful
- True Positives (model said “yes,” and it was right)
- False Positives (model said “yes,” but it was wrong)
- True Negatives (model said “no,” and it was right)
- False Negatives (model said “no,” but it was wrong)
ROC-AUC, Precision, and Recall: Know Your Tradeoffs
- ROC-AUC measures how well your model distinguishes between classes across all thresholds. If the AUC is 0.5, your model’s guessing. If it’s closer to 1.0, you’re in good shape.
- Precision is about how many predicted positives were actually correct.
- Recall is about how many actual positives your model caught.
Model Optimization Strategies: Tuning Without Starting Over
- 1. Hyperparameter tuning
Models like Random Forest or XGBoost come with dozens of knobs—like tree depth, learning rate, or number of estimators. Tools like Grid Search, Random Search, or Optuna (for Bayesian tuning) can help find better settings. It takes time, but the performance jump can be real.
- 2. Feature engineering
Sometimes, the biggest improvements come from the data side. Creating new features (e.g., time between events, ratios, or domain-specific logic) or transforming existing ones (normalization, log scaling) can boost performance more than model tweaking.
- 3. Ensemble methods
Combining models—through stacking, bagging, or boosting—often delivers better accuracy and stability. It’s not always lightweight, but if accuracy matters more than speed, ensembles are worth a look.
- 4. Regularization
If your model’s overfitting, techniques like L1/L2 regularization (in linear models) or dropout (in neural nets) can help. It’s all about reducing model complexity without tanking performance.
In most cases, incremental tuning like this is better than starting over. Small adjustments, tested well, tend to produce solid returns over time.
Evaluate Like Your Business Depends on It (Because It Might)
Want to run a sanity check on your current ML model’s performance?
Explore strategic opportunities and drive your success in the rapidly advancing blockchain landscape.
Why Businesses are Embracing Machine Learning: Strategic Impact, ROI KPIs, and Risk Mitigation
1. Automation: Freeing Human Capital for Strategic Work
- Workforce Optimization: ML automates not just back-office processes but knowledge work—like invoice reconciliation, lead scoring, and anomaly detection. This allows teams to redeploy talent to higher-impact roles.
- Scalability Without Proportional Hiring: Businesses can process more requests, users, or data without linearly increasing headcount.
- Cost Reduction with Intelligence: Unlike rule-based RPA, ML improves over time. The more data it ingests, the more efficient it becomes—delivering long-term operational savings.
- Banking: Automating loan approvals with ML reduces processing time by over 60% while reducing credit risk through intelligent scoring.
- Healthcare: Triage chatbots using ML reduce administrative load on staff by automating appointment handling and symptom checks.
2. Prediction: Turning Uncertainty into Opportunity
- Revenue Growth via Forecasting: Predict which leads are likely to convert, which markets will respond to a product launch, and where demand will spike.
- Operational Precision: Inventory planning, staffing, and logistics become data-driven—reducing waste and overstocking.
- Customer Retention: Early churn prediction allows businesses to intervene before revenue is lost.
- Retail: Dynamic pricing algorithms that predict when consumers are likely to buy—leading to increased conversions and optimized margins.
- Manufacturing: Predictive maintenance systems that prevent machinery failure—reducing downtime by up to 50%.
3. Personalization: Building Customer Relationships at Scale
- Increased Conversion & Engagement: Personalizing the buyer journey boosts conversion rates by up to 30% in e-commerce environments.
- Customer Lifetime Value (CLTV): Personalized engagement leads to increased retention, upsells, and brand loyalty.
- Marketing Efficiency: ML optimizes ad targeting and campaign messaging to deliver the right message to the right user at the right time.
- Media: Streaming platforms recommend content based on deep behavioral models, increasing user watch time and subscription renewals.
- Finance: Banks offer customized financial products and investment plans based on user spending behavior and risk profiles.
4. KPIs That Demonstrate Machine Learning ROI
- Increased conversions through better targeting and recommendations
- New revenue streams from predictive cross-selling or dynamic pricing
- Expansion into high-performing customer segments via segmentation models
- Average order value (AOV)
- Revenue per user/session
- Sales velocity improvements
- Labor savings through intelligent automation
- Reduced error rates in decision-heavy tasks (e.g., loan approvals, fraud reviews)
- Decreased customer acquisition cost (CAC) via improved targeting
- Cost per transaction
- Tickets resolved per support agent
- Total hours saved per process
- ML-driven churn models help intervene before users leave
- Tailored loyalty programs driven by behavioral clustering
- Monthly/quarterly churn rate
- Monthly/quarterly churn rate
- Repeat purchase rate / subscription renewal rate
- ML models optimize logistics, routing, inventory, and workflows
- Inventory turnover ratio
- Cycle time reduction in supply chains
- Error rate drop in manual processing tasks
5. Risk Management: Using ML to Prevent the Preventable
- Payment processors use ML to flag transactions that deviate from normal patterns—reducing fraud loss without hampering user experience.
- Behavioral ML-based endpoint detection flags insider threats or unusual access patterns faster than manual reviews.
- Natural Language Processing (NLP) models review legal contracts for clauses that conflict with updated regulations.
- Supply chain models detect early signals of delays and reroute logistics before service-level agreements are breached.
Strategic ML Investment & ROI Mapping: Making Machine Learning Actually Pay Off
- Should we build or buy?
- When will we see actual ROI?
- Is this just a project, or are we becoming an AI-driven business?
- How do we budget for this without betting the house?
Build vs. Buy: What Makes Sense Right Now?
- You have access to proprietary data that gives you a real edge.
- Your use case is pretty unique or strategic to your offering.
- You’ve got (or are willing to hire) a team of solid data scientists, ML engineers, and DevOps folks.
- You’re dealing with a relatively common ML task (say churn prediction or sentiment analysis).
- You want to test ROI before making a bigger commitment.
- You just don’t want to juggle too many moving parts, especially early on.
ROI Timelines: When Does ML Actually Start Paying Off
ML as a Product vs. ML as a Service: Know What You’re Building Toward
- More UX investment (since end-users interact with the model).
- Strong model accuracy and performance.
- Real-time processing in many cases.
- A dedicated product and engineering team.
- Has a faster time-to-value.
- Requires less frontend complexity.
- Helps validate business ROI before scaling up.
Cost Structure and Resource Planning: Know What You’re Signing Up For
- Experiment tracking (like Weights & Biases)
- Model versioning (like MLflow or DVC)
- Deployment & scaling (AWS SageMaker, Azure ML, Vertex AI)
Wrapping It All Up: Think of ML as a Long-Term Business Asset
- Start small, but plan for scale.
- Choose build or buy based on value, not just cost.
- Set realistic ROI timelines and track them.
- Don’t just “do AI”—treat it like a core capability, not a hobby.
Need help defining your ML roadmap or building a business case for investment?
We’ve worked with companies at every stage—happy to offer a second set of eyes.
Real-World Applications of Machine Learning
1. Predictive Analytics
2. Image Recognition
3. Natural Language Processing (NLP)
4. Time Series Forecasting
5. Anomaly Detection
6. Intelligent Automation
7. Chatbots & Virtual Assistants
8. Dynamic Pricing
9. Recommender Systems
10. Smart IoT With ML
11. Voice Recognition & Assistive Tech
Want to talk through which of these fits your business best?
We’re here to help—no tech speak overload, just clear answers and real outcomes.
Legal, Ethical, and Governance Issues in Machine Learning

1. Data Privacy: It’s Not Optional Anymore
2. Algorithmic Bias and Fairness: A Hidden but Serious Risk
3. Explainability and Transparency: “Because the model said so” Isn’t Enough
4. Regional Regulations: It’s Not One-Size-Fits-All
- United States: So far, there’s no single national AI law. Instead, regulation is piecemeal—think HIPAA for healthcare, Fair Lending Laws for finance, and CCPA for consumer data in California. New laws like the Algorithmic Accountability Act are in the works, but it’s still very state-by-state.
- European Union: The EU AI Act is shaping up to be one of the strictest regulatory efforts yet. It classifies AI applications by risk (unacceptable, high, limited, minimal) and demands serious safeguards for high-risk systems, including transparency and human oversight.
- India: While not heavily regulated just yet, India passed the Digital Personal Data Protection Act in 2023. It mirrors some GDPR principles and signals more rules are coming. Ethical AI guidelines from NITI Aayog are also gaining traction.
- APAC: It’s a mixed bag. Singapore released a Model AI Governance Framework—voluntary but detailed. China, on the other hand, is leaning heavily into AI control, especially around facial recognition and content recommendation algorithms.
5. Ethical AI Frameworks: They’re Not Law, But They’re Useful
- IEEE’s Ethically Aligned Design: One of the more technical documents, it covers autonomy, bias, accountability, and human rights.
- OECD’s AI Principles: Adopted by 40+ countries, this framework emphasizes inclusive growth, human-centered values, and robustness.
- Google’s AI Principles: Yeah, it’s corporate—but it covers practical ground like avoiding harm, being socially beneficial, and building accountability into development.
Bringing It All Together: What Should Businesses Actually Do?
- Make privacy a design principle, not an afterthought. Anonymize, encrypt, and get clear consent.
- Test your models for bias, especially if they impact people’s lives or livelihoods.
- Use interpretable models where it makes sense—or at least add explainability layers.
- Stay on top of regional laws. If you operate in multiple countries, tailor your approach.
- Document everything. Seriously. When regulators (or customers) ask how your ML works, you want answers—not shrugs.
The Future of Machine Learning: Where It's Headed and Why It Matters
1. AutoML and Code-Free AI: Making Machine Learning Less... Machine-y
2. Federated Learning: Privacy-Friendly Collaboration
3. Edge AI and TinyML: Shrinking the Model, Not the Intelligence
4. Machine Learning Meets Blockchain: Trust and Traceability
5. Agent-Based AI and Multi-Modal Learning: A Smarter Class of ML
6. The Long Game: AGI and the Dream of General Intelligence
7. Enterprise Predictions: What ML Will Look Like by 2030
- ML will become part of standard enterprise stacks, just like CRM or ERP systems.
- Hybrid AI teams (data scientists + domain experts + ops + ethics leads) will become the norm.
- AI governance will tighten, especially around explainability, bias audits, and data provenance.
- ML as a Service (MLaaS) will simplify adoption for mid-sized firms—fewer tools to juggle, faster time to value.
- And finally, regulators will catch up, meaning AI compliance won’t be optional—it’ll be table stakes.
Partner With Us to Incorporate Machine Learning to Your Business Operations
Custom ML Model Development
Predictive Analytics That Drive Better Decisions
Text and Language Intelligence (NLP)
Computer Vision for Real-World Impact
Machine Learning-as-a-Service (MLaaS)
Operational Intelligence With MLOps
Intelligent Automation With ML
Scalable Infrastructure and Ongoing Support
Our Team, Expertise, and Track Record