ON THIS PAGE
Progress0%





Our Global Presence :

A credit risk model is essential for evaluating borrower reliability, protecting lenders from potential defaults, and ensuring stable financial operations. With the rise of machine learning, institutions now leverage advanced algorithms to process vast datasets and detect risk patterns with higher accuracy.
Per a report from the World Bank, global non-performing loans reached $1.6 trillion in 2022, highlighting the scale of credit risk worldwide. And according to McKinsey, around 20% of surveyed credit risk executives have already implemented at least one generative AI use case. In addition, 60% expect adoption within a year.
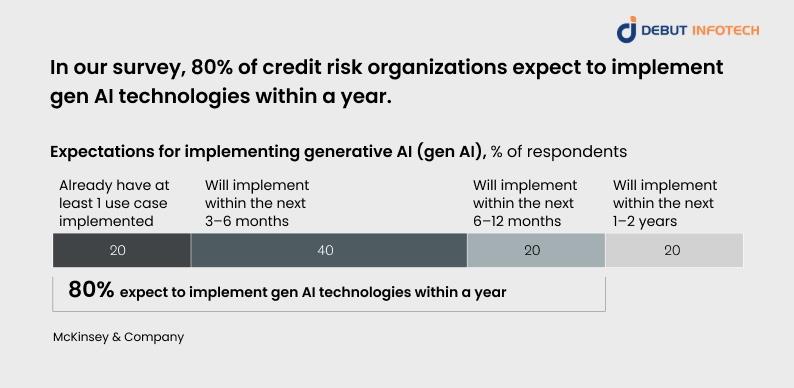
This rapid uptake signals how transformative AI-driven methods are becoming in risk management. By combining traditional approaches with machine learning, financial institutions gain sharper insights, faster decision-making, and stronger compliance frameworks that align with evolving regulatory standards.
In this article, we will cover the impact of credit risk models and machine learning, including, how to build one, and future trends.
A credit risk model is a structured analytical tool that financial institutions use to evaluate the likelihood of a borrower defaulting on their obligations. These models rely on statistical methods, financial ratios, and increasingly advanced machine learning techniques to assess creditworthiness. Their primary function is quantifying risk exposure in lending and investment activities, ensuring decisions are grounded in measurable data rather than assumptions.
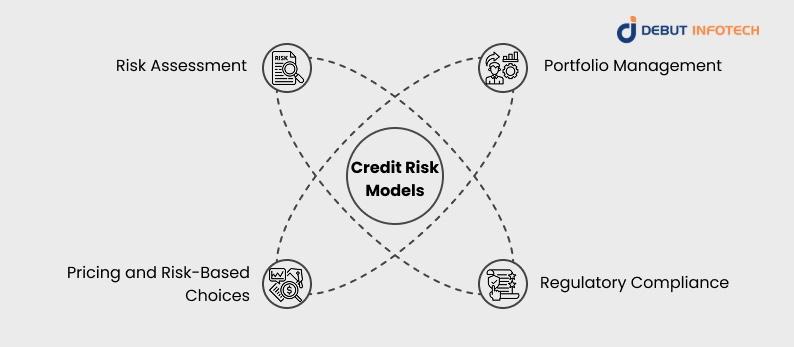
Every financial transaction carries risk, but lending requires extra caution. Credit risk models help institutions evaluate the probability of default before extending credit. By measuring potential exposure, lenders can protect their portfolios and avoid unforeseen losses. This process not only secures profitability but also builds trust with stakeholders.
Credit risk models enable institutions to maintain balance across diversified portfolios. Through ongoing evaluation, they help identify high-risk segments, reduce exposure to vulnerable assets, and optimize risk-adjusted returns. Effective portfolio management ensures financial stability and supports sustainable growth in lending practices.
Pricing in finance should reflect risk, not guesswork. By integrating mainstream financial risk assessment models, lenders can set interest rates that align with each borrower’s profile. This approach fosters fairness—rewarding low-risk borrowers with better terms—while safeguarding lenders from excessive exposure. It’s a forward-looking way of aligning pricing with sustainable lending.
Global financial regulations mandate the use of structured techniques of credit risk management models. Institutions must demonstrate due diligence in assessing creditworthiness to comply with frameworks such as Basel III. By adopting advanced credit risk models, banks ensure regulatory alignment, mitigate penalties, and strengthen credibility with regulators and investors.
Default risk is the most recognized form of credit risk—when a borrower cannot meet repayment obligations. Models are designed to forecast this likelihood, giving lenders a clear signal of when intervention or stricter lending terms may be necessary.
Concentration risk arises when lending activity is heavily weighted toward a single sector, geography, or borrower group. This lack of diversification magnifies potential losses. Identifying and mitigating concentration risk helps institutions preserve portfolio stability.
Credit spread risk reflects the fluctuation of the premium investors demand over risk-free benchmarks. Changes in spreads can impact market valuations of debt instruments. By monitoring these shifts, financial institutions can anticipate volatility and adapt strategies accordingly.
Machine learning enhances prediction accuracy by analyzing vast datasets, including structured financial data and unstructured sources like social media or transaction logs. These models detect subtle patterns that traditional methods may overlook. By leveraging advanced algorithms, institutions reduce misclassifications, leading to more reliable assessments of borrower behavior and default likelihoods.
Real-time decision-making is critical in modern lending environments. Machine learning models process applications instantly, enabling immediate approvals or rejections. This improves customer satisfaction and allows institutions to respond quickly to changing borrower conditions. By reducing delays, lenders minimize risk exposure while enhancing operational efficiency across credit portfolios.
Machine learning solutions adapt seamlessly to growing volumes of credit data. Whether handling thousands or millions of applications, these models maintain performance without compromising speed or accuracy. Flexibility ensures they adjust to evolving borrower profiles, economic conditions, and regulatory changes, making them sustainable solutions for long-term credit risk management.
Borrower behavior is rarely linear, and traditional models often struggle with complex interactions among financial variables. Machine learning addresses non-linearity effectively, capturing intricate relationships in data. By modeling these dynamics, lenders gain deeper insight into risk profiles, producing more accurate assessments that reflect reality.
Risk segmentation becomes far more precise with machine learning. Algorithms categorize borrowers into distinct risk groups, incorporating multiple variables such as spending habits, repayment histories, and external economic signals. This detailed classification empowers institutions to design tailored financial products, optimize interest rates, and maintain healthier, more diversified lending portfolios.
Default prediction models use historical repayment data, behavioral patterns, and external economic signals to estimate the likelihood of borrowers failing to repay. By identifying high-risk individuals early, institutions can adjust lending terms, strengthen monitoring strategies, and reduce losses while maintaining portfolio health and overall credit stability.
Machine learning elevates credit scoring beyond traditional metrics like income and repayment history. It incorporates broader variables such as spending patterns, digital footprints, and transaction histories. These models deliver more accurate, individualized scores, enabling lenders to assess borrower reliability with higher precision and extend credit responsibly across diverse market segments.
Risk-based pricing ensures borrowers are charged interest rates that reflect their true credit risk. Machine learning analyzes multiple borrower attributes in real time, assigning pricing structures tailored to each profile. This helps institutions reward low-risk borrowers with favorable rates while mitigating potential exposure from riskier clients in competitive markets.
Fraud detection benefits significantly from machine learning’s ability to detect anomalies in transaction data. By continuously analyzing patterns, these models can identify suspicious behavior—such as unusual spending or false identities—before financial losses occur. This proactive approach strengthens security, builds customer trust, and safeguards institutional assets against growing cyber threats.
Machine learning enables automation in loan approvals, cutting down manual checks and lengthy processes. By instantly analyzing creditworthiness, lenders can provide rapid, consistent, and objective decisions. This accelerates turnaround times and minimizes human bias, ensuring fairer and more transparent lending practices across diverse customer groups.
Segmentation powered by machine learning groups borrowers into precise categories based on behaviors, financial status, and repayment histories. This allows lenders to personalize services, design targeted offers, and manage risks more effectively. The ability to understand customer differences enhances portfolio performance and strengthens long-term borrower relationships.
Dynamic pricing uses machine learning to adjust loan terms in real time based on borrower risk, market fluctuations, and institutional objectives. By continuously recalibrating rates, lenders remain competitive while ensuring profitability. This flexibility allows institutions to balance market demands with prudent risk management practices.
With machine learning models that monitor borrower behavior over time, credit limit management becomes more accurate. Institutions can increase limits for responsible clients while tightening access for riskier ones. This dynamic adjustment supports customer growth opportunities while reducing exposure to default, strengthening financial resilience for both lender and borrower.
Machine learning enhances collections by predicting which borrowers will most likely repay and which strategies will be effective. This insight allows lenders to prioritize accounts, apply targeted outreach, and reduce costs. The result is improved recovery rates, stronger relationships, and minimized disruptions in cash flow.
Early warning systems use deep learning in predictive analytics to identify borrowers showing subtle signs of financial stress. By detecting risks before defaults occur, institutions can intervene with restructuring options, adjusted repayment schedules, or additional monitoring. This proactive approach reduces losses and promotes more sustainable borrower-lender relationships over time.
a) Data Sources
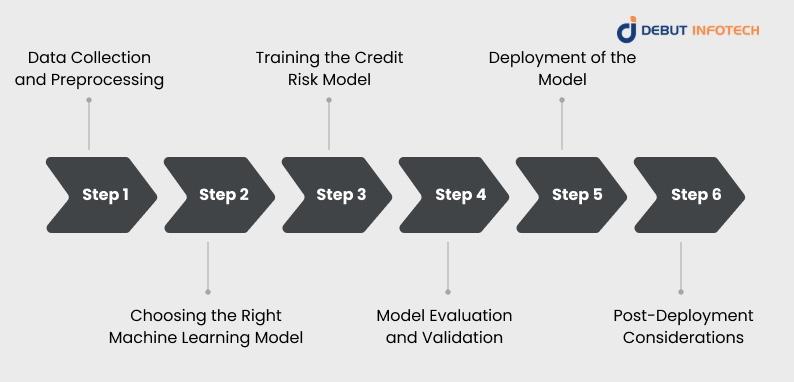
Credit risk data comes from diverse sources, including credit bureaus, bank statements, transaction logs, and alternative data like utility bills or digital activity. Combining structured and unstructured data ensures the model captures borrower behavior comprehensively, enabling more accurate assessments of creditworthiness.
b) Preprocessing Techniques
Preprocessing prepares raw data for modeling through cleaning, normalization, handling missing values, and feature engineering. This step eliminates noise and enhances quality, ensuring the model processes consistent, accurate, and unbiased information to deliver reliable credit risk analytics.
a) Supervised Learning Models
Supervised learning methods like logistic regression, random forests, and gradient boosting use labeled data to predict outcomes such as defaults. They are highly effective in structured credit environments where past repayment histories strongly influence future borrower performance.
b) Unsupervised Learning Models
Unsupervised models detect hidden patterns in credit modelling without labeled outcomes. They cluster borrowers with similar characteristics, helping institutions identify unusual behavior or emerging risk groups. This is particularly useful in credit risk management for early identification of atypical borrower categories.
c) Ensemble Methods
Ensemble methods combine multiple algorithms to improve performance. By blending models such as boosting, bagging, or stacking, lenders achieve greater accuracy and resilience. These machine learning techniques reduce overfitting risks and produce more stable, reliable predictions in complex credit environments.
a) Data Splitting
Data is divided into training, validation, and test sets to prevent overfitting. This ensures the model generalizes well to unseen data, delivering reliable predictions across different borrower groups and market conditions.
b) Hyperparameter Tuning
Tuning involves optimizing model parameters—like learning rate or tree depth—through systematic testing. This fine-tuning process enhances model performance and ensures predictions remain accurate, consistent, and adaptable to real-world lending scenarios.
c) Cross-Validation
Cross-validation evaluates model reliability by testing it across multiple subsets of data. This process confirms consistency, reduces bias, and strengthens confidence that the model performs well under varied borrower profiles and economic conditions.
a) Performance Metrics
Evaluation uses metrics like ROC-AUC, precision, recall, and F1-scores to measure prediction strength for consumer credit risk models via machine learning algorithms. These indicators reveal how accurately the model distinguishes between high- and low-risk borrowers, ensuring balanced assessments in decision-making.
b) Backtesting and Stress Testing
Backtesting compares predictions with historical outcomes, while stress testing simulates extreme conditions such as recessions. These methods validate the model’s resilience, confirming it remains reliable under both normal and adverse financial environments.
a) Integration with Decision Systems
Deployment involves embedding the credit risk assessment model into existing lending platforms and workflows. Integrated models enable seamless credit assessments, automate decision-making, and improve efficiency, ensuring institutions respond quickly to loan applications with accurate, consistent evaluations.
b) Real-Time Scoring
Real-time scoring uses streaming data to evaluate borrower risk instantly. This capability accelerates approvals, improves customer experience, and ensures decisions are based on the most current information, reducing delays and risk exposure for institutions.
a) Monitoring Model Performance
After deployment, continuous monitoring ensures the model remains effective. Tracking prediction accuracy, detecting drifts, and comparing outcomes with expectations helps institutions intervene early, maintaining long-term reliability and stability.
b) Retraining and Model Updating
To remain relevant, credit risk portfolio models must be regularly retrained with fresh data. This adaptation process ensures predictions reflect current borrower behaviors, economic changes, and market conditions, minimizing risks tied to outdated assumptions.
c) Model Governance and Compliance
Governance establishes accountability for machine learning model use, ensuring adherence to legal, ethical, and regulatory standards. Institutions must document processes, audit results, and enforce oversight frameworks to protect integrity and maintain trust in AI-driven credit assessments.
a) Data Privacy and Ethics
Data privacy remains a cornerstone of responsible AI adoption. Financial institutions must protect borrower information through encryption, secure storage, and compliance with global standards such as GDPR. Beyond technical safeguards, ethical practices require fairness—ensuring algorithms avoid bias against vulnerable groups and provide equal opportunities in credit access.
b) Interpretability of Models
One of the main challenges in AI-driven credit modeling is explainability on machine learning platforms. Regulators and customers alike demand transparency in how credit decisions are made. Institutions must ensure models provide interpretable outputs, offering clear reasoning behind risk scores. This fosters trust, reduces disputes, and ensures decisions can withstand regulatory scrutiny.
c) Regulatory Compliance
AI applications in finance operate under strict regulations. Compliance frameworks such as Basel III or local supervisory guidelines require consistent oversight of model accuracy, fairness, and accountability. Financial institutions must maintain documentation, conduct audits, and align practices with these requirements, ensuring that AI-based credit risk models meet legal and ethical obligations.
Explainable AI (XAI) is becoming essential in credit risk modeling, ensuring transparency in how predictions are made. By providing interpretable results, lenders can justify decisions to regulators, auditors, and borrowers. This reduces disputes and builds trust by showing fairness in lending practices, particularly in sensitive credit approval processes.
Federated learning enables financial institutions to collaboratively train credit risk models without sharing raw data, addressing privacy and security concerns. Each participant contributes to a global model while retaining sensitive customer information locally. This innovation promotes stronger industry-wide risk assessment, expands dataset diversity, and enhances prediction accuracy while maintaining compliance with data protection regulations.
Integrating alternative data—such as mobile payment histories, utility bills, and digital footprints—expands credit evaluation beyond traditional metrics. By incorporating these unconventional indicators, lenders can assess thin-file or previously underserved borrowers more accurately. This trend encourages financial inclusion, improves risk segmentation, and allows institutions to reach broader markets with tailored lending solutions.
Debut Infotech has established itself as a reliable partner offering machine learning development services for organizations looking to build advanced credit risk models powered by machine learning.
With expertise in data-driven solutions, they design systems that improve prediction accuracy, streamline decision-making, and ensure regulatory compliance. Our tailored approach helps financial institutions manage risk effectively, adapt to evolving market conditions, and maintain long-term resilience.
By combining technical depth with practical execution, we deliver solutions that align seamlessly with institutional goals.
Integrating credit risk models and machine learning redefines how financial institutions evaluate risk, set pricing, and manage portfolios. By improving prediction accuracy, enabling real-time decision-making, and enhancing compliance, these models provide a resilient foundation for modern credit practices.
With innovations such as explainable AI and alternative data sources shaping the future, lenders have an opportunity to balance growth with responsibility. Institutions adopting these technologies today will be best positioned to strengthen trust, reduce defaults, and achieve long-term financial stability.
A. Credit risk models usually rely on borrower data like income, debt levels, repayment history, and credit scores. Machine learning adds extra layers, pulling in alternative data—transaction patterns, spending behavior, or even utility payments—to capture a fuller picture of someone’s financial reliability.
A. The toughest parts are handling biased or incomplete data, ensuring the models are transparent, and meeting regulatory standards. On top of that, training and maintaining these models requires strong technical expertise, secure data pipelines, and constant monitoring to keep results fair and reliable.
A. It depends on complexity and resources, but typically, it can take anywhere from a few weeks to several months. Gathering and cleaning data often eats the most time, followed by model training, validation, and regulatory approval before it’s ready for real-world use.
A. Costs vary widely depending on scale, data needs, and tech stack. A small proof of concept might run in the tens of thousands, while enterprise-level models can climb into millions. Expenses usually cover data collection, infrastructure, specialized talent, and long-term compliance requirements.
A. Machine learning sharpens predictions by spotting patterns that traditional methods miss. It adapts quickly to new data, improves accuracy in risk scoring, and reduces false approvals or declines. This makes lending decisions fairer, faster, and more efficient, benefiting both financial institutions and their customers.
Our Latest Insights
USA
2501 Chatham, Rd Suite R Springfield, IL 62704
+1-708-515-4004
info@debutinfotech.com
UK
7 Pound Close, Yarnton, Oxfordshire, OX51QG
+44-770-304-0079
info@debutinfotech.com
Canada
326 Parkvale Drive, Kitchener, ON N2R1Y7
+1-708-515-4004
info@debutinfotech.com
INDIA
Sector 101-A, Plot No: I-42, IT City Rd, JLPL Industrial Area, Mohali, PB 140306
9888402396
info@debutinfotech.com
Copyright © 2026, Debut Infotech. All rights reserved. | Privacy Policy


