A Comprehensive Review On Ensemble Modeling: Techniques, Benefits and Application
In this blog, the concept of ensemble modeling will be widely explored, along with a variety of techniques, advantages, and applications.
Published August 28, 2024·Updated January 20, 2026·15 min read
Gurpreet Singh / Author
CEO & Director of AI & Emerging Technologies
Harry Dhillion / Reviewer
Director – Digital Transformation & Customer Success
Make us preferred source on Google
256 views
Share
Make us preferred source on Google
ON THIS PAGE
Progress0%
Achieving high accuracy and trustworthy predictions is crucial in the rapidly expanding fields of machine learning (ML) and artificial intelligence (AI). Robust and scalable models are in high demand as companies depend more and more on machine learning development services to obtain a competitive edge. Combining the advantages of several models into a unified model has been shown to improve model performance through the use of ensemble modeling, a potent Machine Learning technique.
In this blog, the concept of ensemble modeling will be widely explored, along with a variety of techniques, advantages, and applications. After reading this thorough analysis, you will have a better knowledge of ensemble modeling’s role in AI and ML research and how it may be used to increase the precision and dependability of machine learning algorithms.
Unlock the full potential of your data with cutting-edge ensemble modeling solutions.
Explore our advanced Machine Learning Development Services and see how we can help you achieve superior predictive accuracy and business insights.
Ensemble modeling is a machine learning technique that includes merging many models to increase prediction accuracy. The basic idea is that a collection of models can produce forecasts that are more reliable and accurate than any one model working alone. This methodology optimizes the benefits and minimizes the drawbacks of several models, leading to enhanced generalization of novel data.
Essentially, ensemble modeling is similar to putting together a group of specialists, each with a specialized skill set, to work together to solve a problem. An ensemble model can perform better by incorporating the predictions of several machine learning algorithms, much as a team of specialists can outperform a single expert.
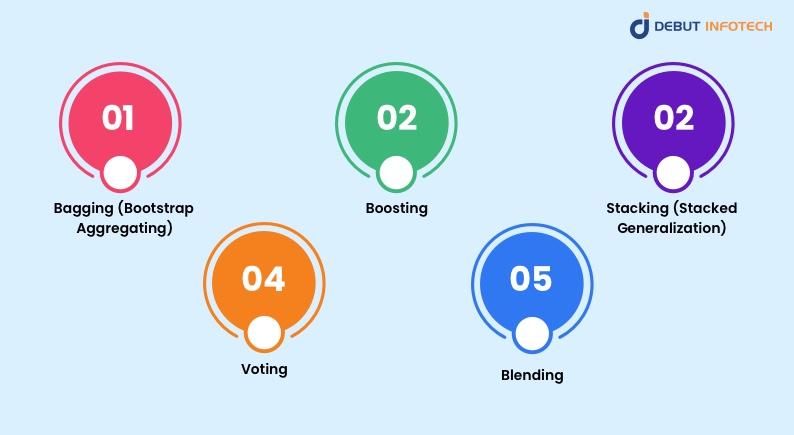
Model Ensembling Techniques
For creating ensemble models, there are a number of well-liked methods available, each with a special method for fusing distinct models. The most often used model ensembling techniques are:
Bagging (Bootstrap Aggregating): One of the easiest yet most powerful ensemble techniques is bagging. It entails using sampling with replacement (bootstrap sampling) to create numerous versions of a training dataset. After training a distinct model on each dataset, the final prediction is generated by averaging (for regression) or voting (for classification) the predictions made by these models. Among bagging examples, the Random Forest algorithm is the most well-known.
For instance, bagging is a method of creating multiple new datasets from a 1000-instance dataset by randomly selecting instances from the original dataset, each used to train a different decision tree, with the average forecast being the final one.
Boosting: Boosting is a sequential ensemble technique that trains models iteratively, correcting flaws in previous models. It assigns greater weight to instances mistakenly predicted in later models, continuing until no further advancements are possible. Popular boosting algorithms include AdaBoost, Gradient Boosting, and XGBoost.
The first model may have a 70% accuracy rate, followed by the second model focusing on 30% of incorrect cases. A weighted summation of all models results in the final projection.
Stacking (Stacked Generalization): Stacking is an advanced ensemble strategy that trains a meta-model to aggregate the predictions of multiple base models. The original dataset is used to train the base models, which serve as input characteristics for the meta-model.
The meta-model then learns how to integrate these forecasts to improve overall efficacy. Base models may use machine learning algorithms like logistic regression, decision trees, and support vector machines. The meta-model, like a neural network, learns how to combine these predictions to create the final forecast.
Voting: Voting is an easy-to-understand ensemble technique in which a voting mechanism is used to integrate the predictions of several separately trained models. In regression questions, the predictions are averaged (soft voting), whereas in classification issues, the final prediction is determined by the models’ majority vote (hard voting).
Example: Under hard voting, class A would be the final forecast if three models were to predict the label for a particular instance and two of them would predict class A while the third would predict class B.
Blending: While blending and stacking are similar, the meta-model is usually trained on a holdout set. By using blending, the meta-model is trained using the base models’ predictions from a validation set after the base models have been trained on a subset of the training data. Because there is less data available to train the meta-model, this method can be less effective than stacking but is frequently easier to execute.
As an illustration, you may divide your data into two sets, using the first set to train the basic models and the second set to produce predictions for the meta-model.
Ensemble Model Algorithms
Using certain ensemble model algorithms created to make model ensembling easier is a common practice while implementing ensemble models. A few of the ensemble model algorithms that are most frequently employed are as follows:
Random Forest: One well-known example of a bagging algorithm is Random Forest. Using several dataset subsets, it constructs numerous decision trees and averages their predictions to increase precision and decrease overfitting. It works especially well for applications involving both regression and classification.
AdaBoost: AdaBoost is a recognized boosting technique that modifies the weights of cases that are mistakenly predicted, compelling later models to concentrate on these more difficult cases. It can greatly increase performance and works well with simple models like decision trees, which are sometimes referred to as “stumps” in this context.
Gradient Boosting Machines (GBM): GBM is a potent boosting ensemble model algorithm that develops models in a sequential fashion, attempting with each new model to rectify the mistakes of its predecessors. Due to its excellent accuracy and capacity to handle complicated datasets, it is frequently utilized in competitions and practical applications.
XGBoost: XGBoost is an enhanced form of GBM that comes with extra capabilities including parallel processing, regularization, and tree pruning. It is often utilized in Kaggle tournaments and other machine learning tasks because of its reputation for speed and performance.
LightGBM: Designed for speed and efficiency, LightGBM is an additional gradient boosting method. It is renowned for its capacity to handle categorical features directly without the requirement for one-hot encoding, making it especially well-suited for huge datasets.
CatBoost: CatBoost is a gradient-boosting technique created especially for effective handling of categorical data. It is an appealing choice for datasets with plenty of categorical features since it automates the preprocessing of categorical variables.
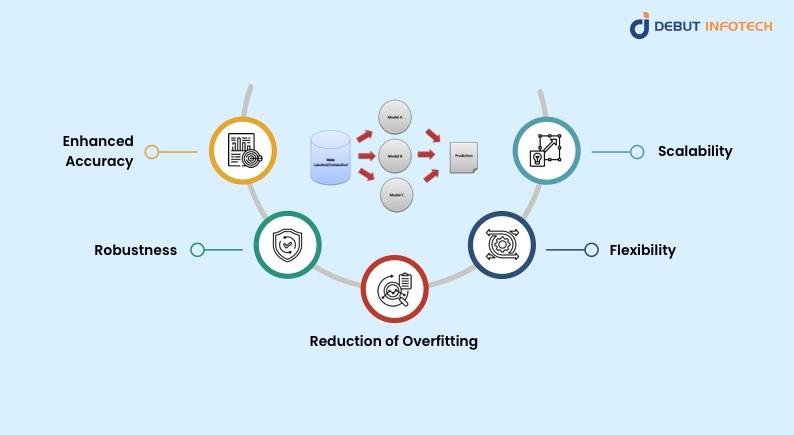
Benefits of Ensemble Modeling
Using ensemble models has a number of important benefits over using single models, including:
Enhanced Accuracy: By pooling their advantages, ensemble models usually perform better than individual models. As a consequence, new data may be predicted more accurately and broadly. For example, compared to single models, ensemble approaches lowered the error rate by 10-15%, according to research.
Robustness: Ensemble approaches lessen the impact of individual model errors by combining the predictions of several models. Predictions become more robust and trustworthy as a result, particularly in noisy or complicated datasets.
Reduction of Overfitting: When a model does well on training data but badly on unknown data, it is said to be overfitted. Overfitting can be reduced using ensemble models, especially those that employ boosting and bagging strategies, which average out prediction variance and noise.
Flexibility: Because ensemble modeling is so flexible, it can be used to combine several model types, including support vector machines, decision trees, and neural networks. This allows several algorithms to be combined into a single, cohesive model, utilizing their own strengths.
Scalability: Large datasets and complicated tasks can be handled with ease by ensemble approaches. Large amounts of data may be processed effectively by algorithms such as XGBoost and LightGBM, which makes them perfect for real-world applications.
The choice of base models, the ensemble technique, and the available computational resources are only a few of the elements that must be carefully taken into account during the implementation of ensemble models in machine learning research. The following is a step-by-step instruction for using ensemble models:
Select Base Models: Selecting the basis models is the first stage in creating an ensemble model. These models ought to be varied and complimentary, which means they ought to have various advantages and disadvantages. Neural networks, linear models, and decision trees are popular options.
Choose an Ensemble Technique: Next, decide which model ensemble technique is best for the given problem. In the event that you’re faced with a classification task including noisy data, bagging techniques such as Random Forest may be a suitable option. Boosting (such as XGBoost) may be better appropriate for applications demanding great precision.
Train Base Models: Each model should be trained using the training data after the ensemble technique and basic models have been chosen. Make sure that the models are trained on various subsets of the data if you plan to use boosting or bagging.
Combine Predictions: Using the selected ensemble technique, integrate the predictions made by the basis models after they have been trained. For instance, in stacking, you would train a meta-model to integrate the predictions, whereas in bagging, you would average them.
Evaluate Performance: Finally, use cross-validation or a validation set to assess the ensemble model’s performance. Examine its recall, accuracy, precision, and other pertinent metrics in comparison to each base model separately.
Optimize and Deploy: Adjust hyperparameters or add more base models to the ensemble model as needed to make it more precise. After the model has been optimized, put it into use in a real-world setting to make sure it can handle data from the real world.
Ensemble models have been effectively used in a variety of disciplines, demonstrating their adaptability and efficiency in resolving challenging issues. The following are a few aplications of ensemble models and the notable effects they have had:
Finance: In the financial services industry, ensemble models are used for things like automated trading, fraud detection, and credit rating. They anticipate consumer behavior, identify abnormalities, and enhance trading tactics by combining predictions from several ML algorithms. For instance, they lessen false positives and negatives in credit scoring to produce judgments that are more accurate.
Healthcare: When it comes to patient risk assessment, disease diagnosis, and tailored therapy, ensemble modeling is an essential tool in healthcare. It provides precise forecasts and better patient outcomes by combining data from genetics, medical imaging, and electronic health records. For example, it can forecast the chance of an illness.
Marketing and Customer Segmentation: Marketing professionals utilize ensemble models to improve consumer segmentation, forecast customer attrition, and optimize promotions. Businesses can obtain deeper insights into customer behavior by merging various models, which leads to more effective targeting and higher customer retention. This method guarantees precise and useful segmentation.
Image and Speech Recognition: To enhance speech and picture recognition systems, ensemble models are frequently employed in computer vision and natural language processing. They improve tasks such as object detection, facial recognition, and speech-to-text conversion by combining predictions from different deep learning models.
Natural Language Processing (NLP): Ensemble models enhance NLP applications like text categorization, sentiment analysis, and language translation by combining predictions from transformers, RNNs, and SVMs. For instance, an ensemble model classifying customer evaluations may result in more accurate sentiment analysis.
E-commerce: By combining collaborative filtering, content-based filtering, and machine learning, ensemble models in e-commerce enhance recommendation systems, forecast product demand, and optimize pricing strategies, leading to more tailored recommendations and more sales.
Autonomous Vehicles: Ensemble modeling is crucial for autonomous vehicle development, integrating predictions from multiple sensors and models like LIDAR, radar, and cameras. This improves the vehicle’s ability to navigate challenging environments, identify obstacles, and make safe decisions.
Energy Sector: By integrating forecasts from many models, including time series, machine learning, and weather forecasting, ensemble models in the energy sector increase forecast accuracy and resource allocation and guarantee that energy production and consumption are in balance.
Challenges and Considerations in Ensemble Modeling
While ensemble modeling offers numerous benefits, it also presents certain challenges and considerations:
Computational Complexity: Due to the requirement of training numerous models and combining their predictions, ensemble models frequently require more computing power than individual models. This may result in increased resource requirements and training times, particularly for large datasets.
Interpretability: Interpreting ensemble models, particularly deep learning models, can be challenging in industries like healthcare and finance. To improve interpretability, simpler models can be used as base learners or methods like SHAP and LIME can be used to explain the ensemble model’s predictions.
Overfitting: Even though ensemble models typically resist overfitting, it is nonetheless possible, particularly if the basis models are very complicated or the ensemble approach is not adjusted effectively. Defective generalization to fresh data might result from overfitting.
Data Requirements: Ensemble models require large amounts of data for effective training, like stacking and boosting. Limited data can lead to poor performance and overfitting. Techniques like data augmentation, synthetic data generation, and transfer learning can improve ensemble model performance.
Implementation Complexity: Due to the need for specific knowledge in model selection, tuning, and appropriate prediction mixing, the implementation of ensemble models may provide greater challenges than single-model approaches. Model selection, tuning, and ensembling can be automated by machine learning tools and libraries such as H2O.ai, TPOT, and AutoKeras.
The Role of Machine Learning Development Services in Ensemble Modeling
There is an increasing need for specialized machine learning development services as ensemble modeling gains more traction. These services guarantee that organizations can fully utilize the potential of this effective technology by giving them the knowledge and resources required to deploy and optimize ensemble models.
Services for machine learning development provide a number of important advantages.
Expertise: A variety of ML algorithms and ensemble techniques are gathered by machine learning development services. This knowledge is essential for choosing the appropriate models, fine-tuning hyperparameters, and guaranteeing the accuracy and efficiency of the ensemble model.
Customization: Ensemble models can be made to fit a business’s unique requirements by using machine learning development services. These services offer specialized solutions that support corporate objectives, whether they are related to increasing demand forecasting, refining a fraud detection model, or optimizing a recommendation system.
Scalability: Robust infrastructure and the capacity to manage big datasets are necessary for the large-scale implementation of ensemble models. Machine learning development services give ensemble models the tools and assistance they need to scale and function well in real-world settings.
Conclusion
With its capacity to improve the performance, robustness, and dependability of predictive models, ensemble modeling has emerged as a crucial tool in the machine learning space. Ensemble techniques are an essential part of contemporary machine learning development & AI development services because they can produce better results than single-model approaches by integrating the strengths of numerous models.
Ensemble modeling is opening the door for more precise, dependable, and scalable AI solutions, whether they are used to improve financial forecasting, improve customer segmentation, or advance healthcare diagnostics.
In summary, ensemble modeling adoption is not merely a trend but also a need in the cutthroat field of AI and ML. In the era of data-driven decision-making, businesses can uncover new opportunities by utilizing the methods, advantages, and applications of ensemble models.
Ready to transform your business with AI?
Contact Debut Infotech’s team of professionals today to learn how we can implement customized ensemble models tailored to your specific needs.
An ensemble model combines the predictions of multiple machine learning models to improve overall accuracy and robustness. By leveraging the strengths of different models, ensemble techniques can achieve better performance than individual models.
Q. How does ensemble modeling enhance the performance of machine learning algorithms?
Ensemble modeling enhances performance by reducing errors, minimizing overfitting, and improving generalization. By combining predictions from diverse models, ensemble methods create more accurate and reliable predictions.
Q. What are the common techniques used in model ensembling?
Common ensemble techniques include bagging (e.g., Random Forest), boosting (e.g., AdaBoost, XGBoost), stacking, and voting. Each method combines multiple models in different ways to optimize predictive performance.
Q. What are the benefits of using ensemble models in machine learning development?
Ensemble models offer improved accuracy, robustness, and resistance to overfitting. They provide a more reliable and generalizable solution, making them ideal for complex and high-stakes applications like finance, healthcare, and autonomous systems.
Q. Can ensemble models be used with any type of machine learning algorithm?
Yes, ensemble models can be built using various machine learning algorithms, including decision trees, neural networks, support vector machines, and others. The choice of algorithms depends on the specific problem and ensemble technique.
Q. What are some real-world applications of ensemble models?
Ensemble models are used in finance for credit scoring and fraud detection, in healthcare for disease prediction, in marketing for customer segmentation, and in autonomous vehicles for sensor fusion and obstacle detection.
Q. How do machine learning development services assist in implementing ensemble models?
Machine learning development services offer expertise, customization, scalability, and continuous optimization, helping businesses effectively implement and maintain ensemble models for various applications, ensuring they achieve the best results.
A technology leader with 28 years of experience, specializing in AI consulting, business transformation, and enterprise innovation. Works with CXOs to prioritize high-value AI use cases, assess readiness, and shape responsible roadmaps across generative AI, machine learning, NLP, and computer vision.
Harry Dhillion
Director – Digital Transformation & Customer Success